
新特性!基于 eBPF 的容器级块设备 IO 延迟检测
云原生环境中,当业务响应变慢,如何快速界定是计算瓶颈还是存储瓶颈?如果是存储问题,又如何精准定位到是哪个容器、哪块磁盘,甚至哪个 IO 阶段在拖后腿?HUATUO (华佗) 项目提供的块存储IO延迟检测特性,正是解决此类问题的利器。它基于 eBPF 技术,实现了对 Linux 块设备 IO 延迟的精细化、低开销观测。
功能与场景
不只看到“慢”,更看清“为何慢”。
此特性并非采集 iostat 这类传统的平均等待时间,而是深入到 IO 的生命周期,提供直方图式的延迟分布,并支持按容器和磁盘维度进行聚合。
它主要暴露以下核心指标:
| 指标名称 | 含义 | 实用价值 |
|---|---|---|
blkdisk_q2c |
IO 从进入队列到完成的总延迟 | 反映应用感知到的完整IO等待时间 |
blkdisk_d2c |
IO 从被设备派发到完成的硬件延迟 | 直接反映磁盘设备的真实服务能力 |
blkdisk_freeze |
磁盘因 IO 错误等进入冻结状态的次数 | 预警存储硬件的亚健康或故障 |
这几项指标,构成了我们分析IO性能的“铁三角”,在以下场景中极具实战价值:
-
场景1:定位噪声容器
宿主机上一个应用变慢,通过观察每个容器的
blkdisk_q2c延迟分布,可立刻发现某个后台批处理容器的IO延迟畸高,从而确认是它在大量抢占磁盘带宽。 -
场景2:区分软件排队与硬件瓶颈
如果
blkdisk_q2c延迟高,但blkdisk_d2c延迟正常,问题大概率出在内核IO调度队列过长,即压力大但磁盘还行。反之,如果两者都高,则说明硬件设备本身已达性能极限。 -
场景3:存储硬件故障预警
监控
blkdisk_freeze指标,一旦其数值开始增长,往往意味着磁盘出现了坏道、链路不稳等问题,是硬件故障的早期信号,可及时介入处理,避免数据丢失。
使用指南
HUATUO 将上述指标暴露为 Prometheus 格式,你可以通过 curl localhost:19704/metrics 来抓取。结合 Grafana 面板,可以快速构建起存储性能监控视图。以下是两个典型的使用方法:
快速诊断:识别高延迟容器
在容器起压测试或怀疑有 IO 争抢时,先不用看曲线,直接查看当前所有容器的 IO 延迟分位数。
# 查询容器在所有磁盘上的IO总延迟 (Q2C) 桶分布
curl -s localhost:19704/metrics | grep 'container_blkdisk_q2c'
根据返回的标签(container_id, disk, zone),你可以迅速锁定哪个容器在哪块盘上正经历高延迟。zone 标签代表不同时延区间,让你了解延迟分布。
深入分析:关联磁盘硬件延迟
一旦定位到嫌疑容器和磁盘,下一步就是判断问题是出在排队还是硬件。
# 针对特定磁盘 (如 sda) 查询硬件延迟 (D2C)
curl -s localhost:19704/metrics | grep 'blkdisk_d2c{disk="8:0"}'
对比 blkdisk_q2c 和 blkdisk_d2c 在对应 zone(高延迟区间)的计数,若 d2c 也开始在高延迟区间出现,说明硬件响应已变慢。若 d2c 正常而 q2c 很高,优化方向应聚焦于调整IO调度器或应用自身的IO模式。
Linux 内核 Block IO 路径
要理解这些指标从何而来,需要先对Linux内核的块IO流程有一个清晰认识。下图简化了单个IO请求的生命周期。
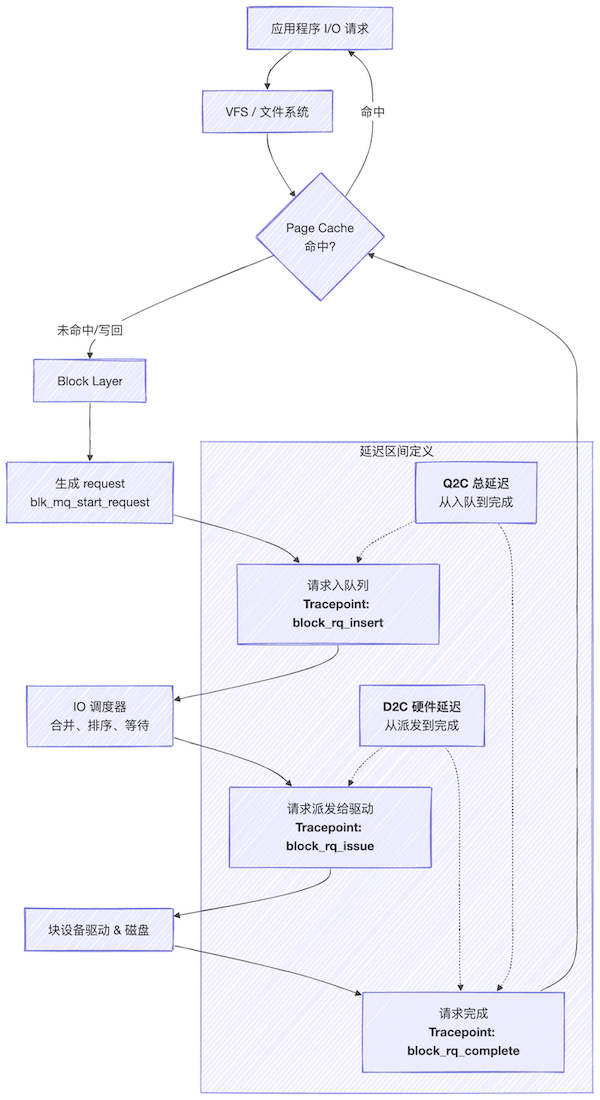
关键阶段说明:
-
Q2C (Queue to Complete):
从IO请求被放入调度队列开始,直到它被标记为完成。这个阶段,包含了在队列中的等待时间和硬件处理时间。
-
D2C (Dispatch to Complete):
从IO请求被调度器派发给底层驱动,到最终完成。它主要反映了硬件设备自身的处理延迟。
-
Freeze:
当磁盘控制器遇到IO超时、致命错误时,内核会冻结该请求队列,阻止新IO下发,这是应对异常的保护机制。
HUATUO 实现机制
HUATUO 如何在不修改内核代码、不重启应用的情况下,高效地捕获这些精细指标?这得益于其内核态eBPF探针 + 用户态数据聚合的经典架构设计。

核心实现细节:
-
精确的内核挂载点
HUATUO 的 BPF 程序(位于
bpf/目录)巧妙地挂载到了block:block_rq_issue和block:block_rq_complete这两个原始追踪点。这避开了复杂的块层多队列实现,直接抓住了IO“派发”和“完成”这两个最关键的瞬间。 -
双维度的数据聚合
在
iolatency_tracing.go中定义了两个核心结构体BlkDiskEntry和BlkgqEntry,分别对应从 BPF Mapblkdisk_map(按磁盘) 和blkcg_map(按cgroup) 读取的数据。这说明eBPF程序在内核中就已经按这两个维度进行了区分与计数。 -
高效的容器关联
updateContainerBlkDisk方法揭示了用户态代理如何动态维护容器与cgroup (blkio子系统) 的映射关系。它定期(每20秒)扫描本机容器列表,将新容器信息写入BPF Map,并清理已销毁容器的条目。这使得后续采集的cgroup级延迟数据能够被准确打上容器标签。 -
低噪声的直方图输出
iolatency_collector.go中的fetchContainerIOlatency和fetchBlkDiskIOlatency方法将BPF Map内的数据dump出来,根据预先定义的时延区间(Zones)进行标准化,最终生成带有zone标签的 Gauge 型 Prometheus 指标。这种设计使得数据量可控,查询效率高。
总结
HUATUO 的块存储 IO 延迟检测功能,诠释了 eBPF 在可观测性领域的核心优势:内核透视、动态追踪与极小性能影响。它将以往需要依靠众多工具、复杂经验才能推断的IO问题,简化为几个清晰的指标。无论是用于日常监控看板,还是应急时的故障排查,都能显著提升效率,是一件不可或缺的利器。