
RDMA 关键技术研究:Doorbell, UAR
UAR, User Access Region
UAR, User Access Region
PCI 地址空间的一部分,内部包含设备内存、寄存器(用户可通过寄存器控制设备)。UAR 以 PCI BAR 的方式暴露其内存空间地址并以 IO-mapped 的方式映射到内核空间,UAR 通常占用一个系统页内存。驱动层为不同进程映射不同的 UAR 以便实现资源隔离,此外 CPU 可以直接访问映射后的内存,减少内核态用户态的上下文切换,降低延迟。UAR 非常典型的用途是门铃寄存器,用户态进程可以直接写门铃寄存器触发硬件操作。UAR 在网卡通信,存储服务,GPU计算等场景均有应用。mellanox 网卡 UAR Page format 布局主要组成:
- Completion WQ DoorBells: 存储在 CQ 寄存器
- Event WQ DoorBells: 存储在 EQ 寄存器
- Send DoorBells: 存储在 Blue Flame 寄存器
UAR 内存布局
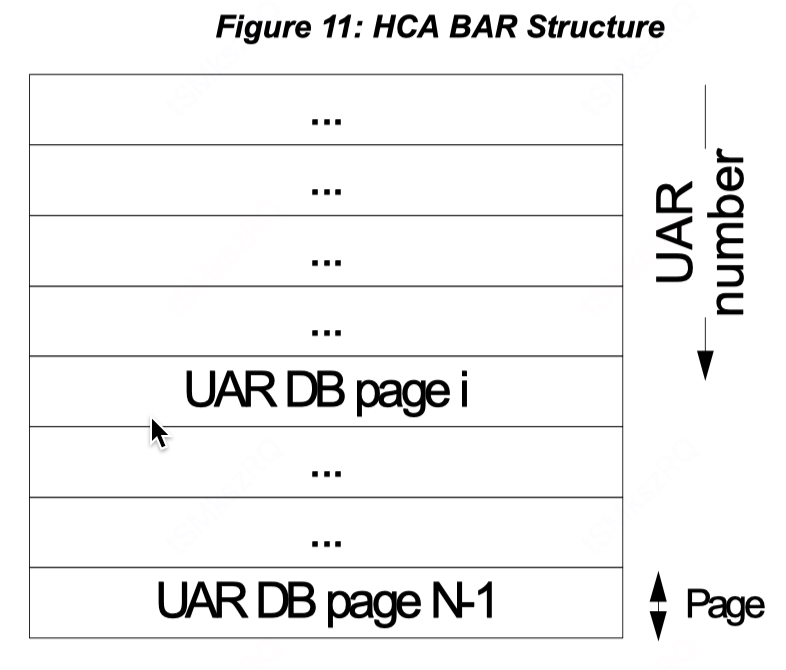
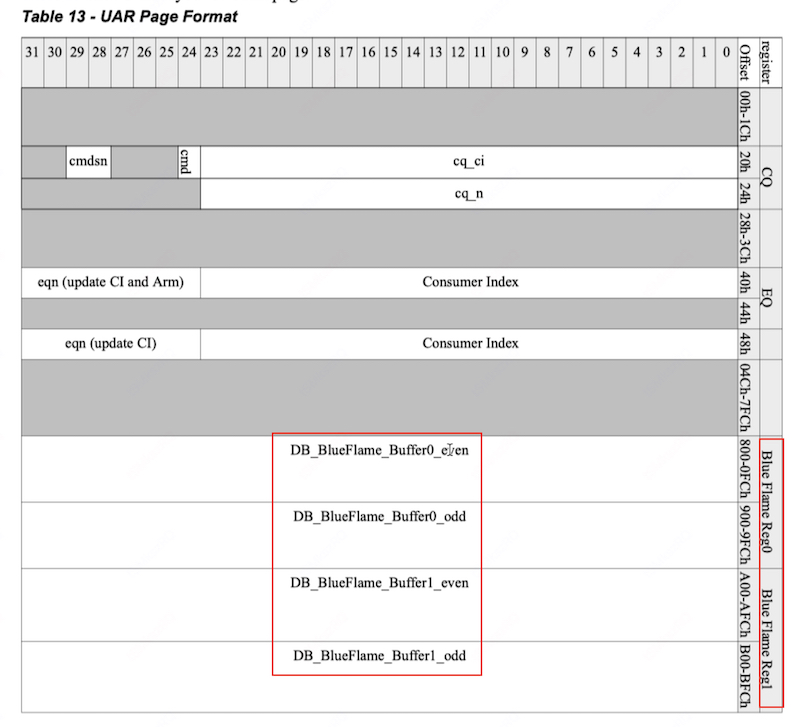
Blue Flame Reg
Mellanox 为了快速访问硬件资源而实现的一项技术,用户可以直接向设备写入 WQEs,因此设备无需再从主机拷贝内存,进而降低延迟。具体实现上,BlueFlame 由一组大小一致的寄存器组成,每寄存器 512B,寄存器又分成两个大小一致的 Blue Flame Buffer 缓存。
Doorbell Record
位于系统物理内存,并在创建 RQ/SQ 时将 Doorbell Record 内存地址赋值到硬件。DoorBell Record 主要存储 SQ sq_wqebb_counter 以及 RQ、SRQ wqe_counter,这些标记表示向硬件队列提交的 WQEs 数目。
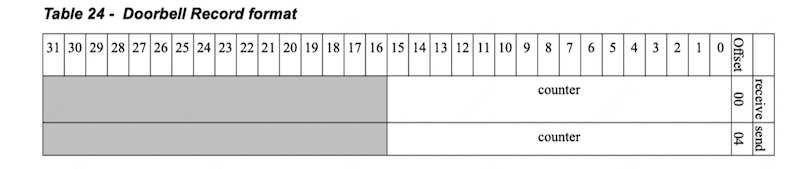
向工作队列提交请求的过程
- Write WQE to the WQE buffer sequentially to previously-posted WQE (on WQEBB granularity).
- Update Doorbell Record associated with that queue by writing their sq_wqebb_counter or wqe_counter for send and RQ respectively
- For send request ring DoorBell by writing to the Doorbell Register field in the UAR associated with that queue. For performance-critical send WQEs DoorBell can be rang by using the BlueFlame mechanism.
注意 1. 对于发送请求而言执行第三步是为了确保WQE被执行。在第二步的时候 HW 已经执行了 WQE,对于已经执行的 WQE 再次敲门铃并无伤害,硬件会忽略该事件。2. 软件可以在第一步批量的提交 WQEs,在第二步更新的参数包含所有的 WQEs。
Doorbell Record 资源映射
资源的分配流程:ibv_create_qp … mlx5_create_qp … mlx5_alloc_dbrec … 内核 create_user_qp:
- 分配 Doorbell Record 内存
- 将该内存的虚拟地址传送给内核驱动
- 驱动对这块内存进行物理分配,锁页,dma 映射等
- 最后赋值到 QPC,创建硬件资源 QP
用户态代码:
providers/mlx5/verbs.c
mlx5_create_qp
qp->db = mlx5_alloc_dbrec 返回一段虚拟内存,这块内存未来用于发送和接收的 Doorbell Record。
qp->db[MLX5_RCV_DBR] = 0;
qp->db[MLX5_SND_DBR] = 0;
cmd.db_addr = (uintptr_t) qp->db; 传送给内核。
...
内核驱动代码:
mlx5_ib_create_qp create_user_qp
mlx5_ib_db_map_user 分配物理内存,锁页,映射。
MLX5_SET64(qpc, qpc, dbr_addr, qp->db.dma); 将该内存 dma 地址赋值至硬件。
...
mlx5_ib_db_map_user(unsigned long virt ...)
page = kmalloc();
page->user_virt = (virt & PAGE_MASK);
page->umem = ib_umem_get();
db->dma = sg_dma_address();
...
Doorbell Register 资源映射
将 BFREG 寄存器映射到用户态,主要涉及 ibv_open_device、ibv_create_qp 操作:
- ibv_open_device … mlx5_alloc_context … 内核 mlx5_ib_alloc_ucontext:
- 分配设备上下文
- 硬件分配 UAR
- 用户映射 UAR
- ibv_create_qp … mlx5_create_qp … 内核 create_user_qp:
- UAR ID 关联 QP
- 返回可用 UAR 索引
1. ibv_open_device UAR 映射
-
ibv_open_device 用户态代码(1):
ibv_open_device mlx5_alloc_context // 请求的寄存器数量,默认 16,可通过环境变量 MLX5_TOTAL_UUARS 配置。 req.total_num_bfregs = context->tot_uuars; // 请求的低延迟寄存器数量,默认 4,可通过环境变量 MLX5_NUM_LOW_LAT_UUARS 配置。 req.num_low_latency_bfregs = context->low_lat_uuars; req.lib_caps |= (MLX5_LIB_CAP_4K_UAR | MLX5_LIB_CAP_DYN_UAR); // 调用至内核 mlx5_ib_alloc_ucontext 返回设备属性 mlx5_cmd_get_context(req, resp ... ) ... // 根据返回的设备属性,初始化设备上下文,以及 UAR 映射等。 mlx5_set_context -
alloc_ucontext 内核态代码(1):IB 设备通过 ib_device_ops.alloc_ucontext 分配内核态设备上下文,并将这些信息存储在结构体 ibucontext 或私有结构体 mlx5_ib_ucontext。
mlx5_ib_ucontext 结构体成员 mlx5_bfreg_info 维护着 UAR 信息, struct mlx5_ib_ucontext { struct ib_ucontext ibucontext; struct mlx5_bfreg_info bfregi; ... }; struct mlx5_bfreg_info { u32 *sys_pages; // UAR ID int num_low_latency_bfregs; unsigned int *count; u32 num_sys_pages; u32 num_static_sys_pages; u32 total_num_bfregs; u32 num_dyn_bfregs; };网卡硬件可能在不同的平台使用,平台支持的页大小可以根据内核编译选项CONFIG_PAGE_SHIFT配置,通常为4K。另外需要明白,每 UAR 包含 BFREG 的总数为 NUM_BFREGS_PER_UAR 4,其中 MLX5_NUM_NON_FP_BFREGS_PER_UAR 2 用于慢速路径 No Fast Path。内核实现上 mlx5_ib_alloc_ucontext calc_total_bfregs 根据请求和硬件配置信息,初始化 mlx5_bfreg_info,最后调用 mlx5_ib_alloc_ucontext allocate_uars 分配硬件 UAR。Mellanox 创建硬件 UAR 资源命令参数和返回值如下图。
calc_total_bfregs // 一个 UAR 对应一个系统页(4K)。每 UAR 包含 NUM_BFREGS_PER_UAR(4) BFREG,其中两个用于非快速路径 MLX5_NUM_NON_FP_BFREGS_PER_UAR。 // total_num_bfregs 16 静态寄存器(用户态申请的寄存器数目) // 而每 UAR 支持 MLX5_NUM_NON_FP_BFREGS_PER_UAR(2) 慢速路径寄存器,因此需要 8 UAR,也就是 8 系统页。 bfregi->num_static_sys_pages = 8; bfregi->num_dyn_bfregs = 1024; // 动态寄存器,默认 1024 bfregi->total_num_bfregs = req->total_num_bfregs + bfregi->num_dyn_bfregs; // 动态+静态寄存器 1040 bfregi->num_sys_pages = req->total_num_bfregs / 2; // 需要总系统页数量 8 bfregi->sys_pages = kcalloc(bfregi->num_sys_pages, ....);allocate_uars 分配 num_static_sys_pages 硬件UAR资源 for (i = 0; i < bfregi->num_static_sys_pages; i++) { // sys_pages 存储 UAR ID,该信息由硬件返回。 mlx5_cmd_alloc_uar(dev->mdev, &bfregi->sys_pages[i]); }
-
ibv_open_device 用户态代码(2):用户态程序根据内核返回的信息完成 UAR 资源映射:
(gdb) p *resp $4 = { bf_reg_size = 512, // BF 寄存器内存大小 tot_bfregs = 16, // BF 静态寄存器数 num_dyn_bfregs = 1024, // BF 动态寄存器数 num_uars_per_page = 1, // UAR 每系统页包含的数量 log_uar_size = 12, // UAR 内存等于 4K qp_tab_size = 262144, cache_line_size = 64, max_sq_desc_sz = 1024, max_rq_desc_sz = 512, max_send_wqebb = 32768, max_recv_wr = 32768, max_srq_recv_wr = 32768, num_ports = 1, flow_action_flags = 0, comp_mask = 3, response_length = 72, cqe_version = 1 '\001', cmds_supp_uhw = 3 '\003', eth_min_inline = 2 '\002', clock_info_versions = 1 '\001', hca_core_clock_offset = 0, dump_fill_mkey = 1792 } ibv_open_device ... mlx5_alloc_context ... mlx5_set_context ... gross_uuars = context->tot_uuars / MLX5_NUM_NON_FP_BFREGS_PER_UAR * NUM_BFREGS_PER_UAR; 总共 32 BFREG 寄存器 context->bfs = calloc(gross_uuars, sizeof(*context->bfs)); num_sys_page_map = context->tot_uuars / (context->num_uars_per_page * MLX5_NUM_NON_FP_BFREGS_PER_UAR); // 8 UAR 内存映射 for (i = 0; i < num_sys_page_map; ++i) { // context->uar 映射 mlx5_mmap(&context->uar[i], i, cmd_fd, ... MLX5_UAR_TYPE_REGULAR); } // 将 context->uar[].reg 平铺赋值到数组 context->bfs[].reg ... -
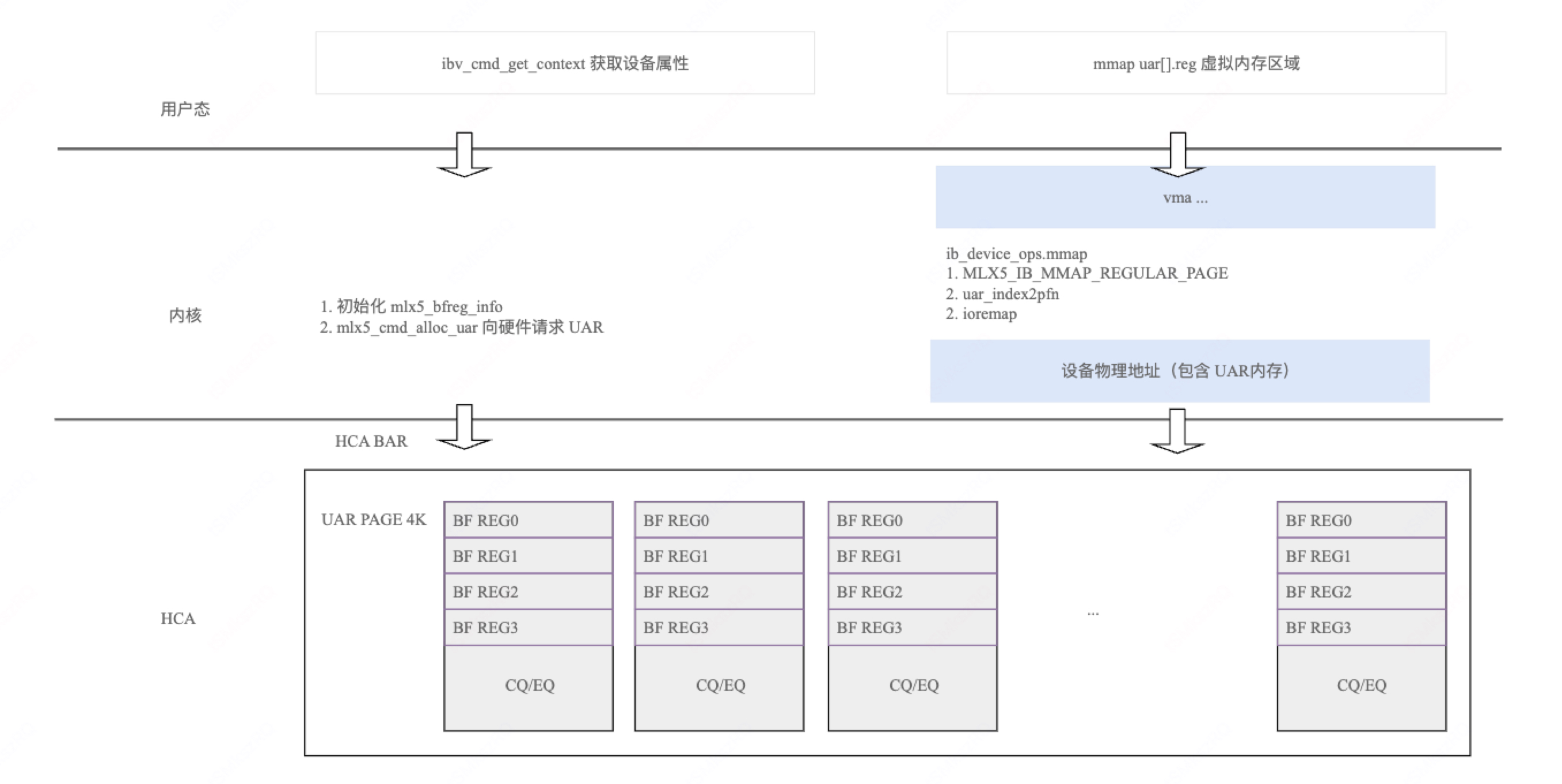
mlx5_mmap 内核态代码(2): mmap 将硬件资源(如寄存器、内存区域)暴露为用户空间可访问的地址,允许用户态程序绕过内核,直接操作这些硬件资源。这种方式避免上下文切换和数据复制,减少延迟,提高吞吐量。在 Mellanox 实现中 mmap 实现了 UAR 资源的映射。UAR 映射的过程:获取用户态传递过来的index索引,根据该索引获取PCIe 地址,最后 remap 设备地址和 vma 用户态地址。
ib_device_ops.mmap = mlx5_ib_mmap int mlx5_ib_mmap(struct ib_ucontext *ibcontext, struct vm_area_struct *vma) // offset 包含了操作类型和UAR INDEX command = get_command(vma->vm_pgoff); case MLX5_IB_MMAP_REGULAR_PAGE: // 1. 根据 vm_pgoff 获取命令操作 // 2. 根据 vm_pgoff 获取 UAR 索引,进而得到设备物理地址 // 3. 将物理地址和vma 虚拟地址进行 remap 映射 uar_mmap(dev, command, vma, context); ... -
最终映射关系图
2. ibv_create_qp UAR QP 关联
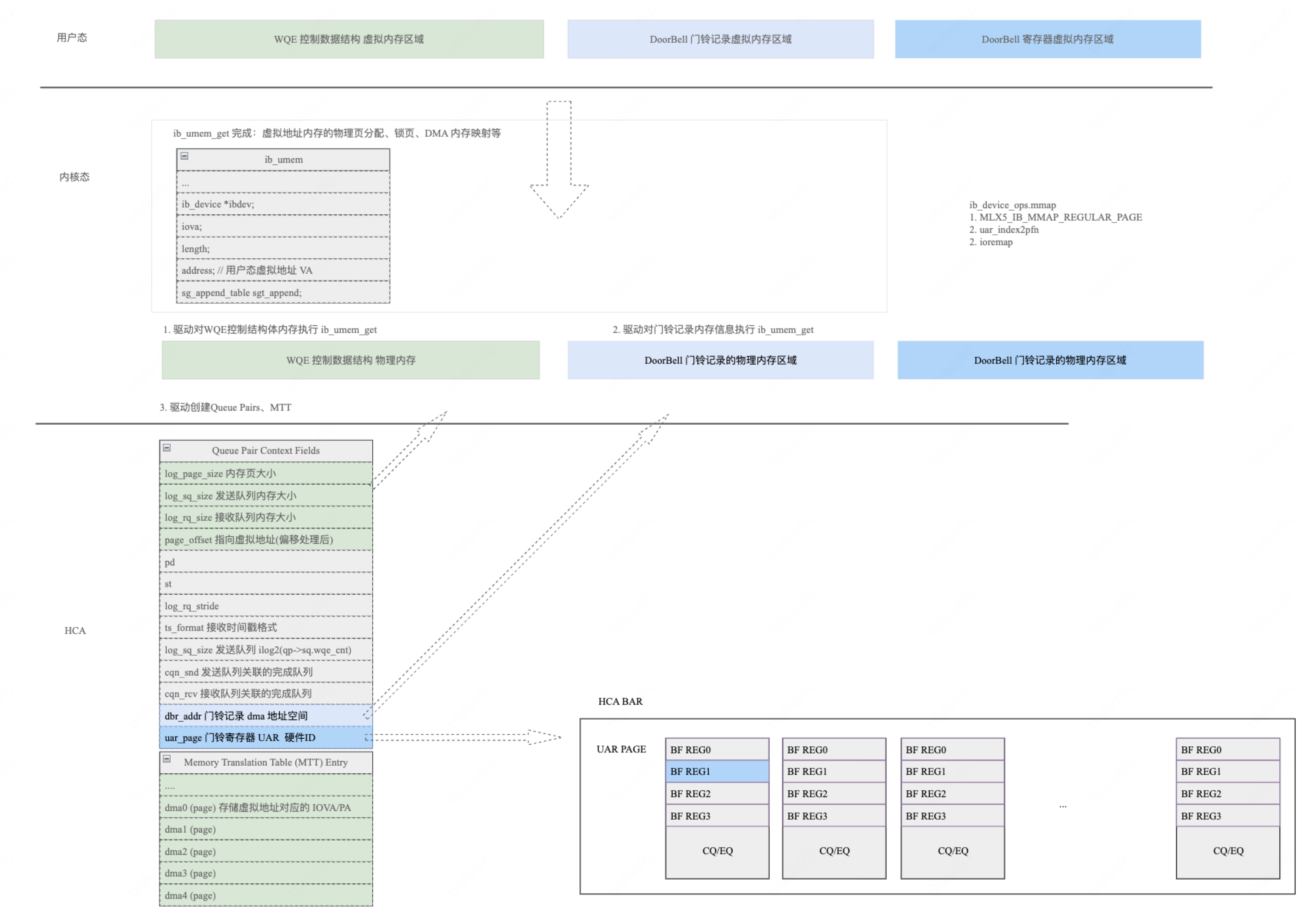
mlx5_create_qp 主要完成 QP 和特定的 UAR 关联。
用户态代码:
mlx5_create_qp
ibv_cmd_create_qp_ex 创建 QP。
// 1. 创建的新 QP 并不是关联所有 UAR 资源而是根据返回的 bfreg_index 确定使用的 UAR。
// 2. qp->bf = &ctx->bfs[uuar_index]; 将该寄存器赋值到 qp,其实 ibv_open_device 后支持16个寄存器。
map_uuar(context, qp, resp_drv->bfreg_index, bf);
内核代码:
create_user_qp
// 1. 从已经分配的 context->bfregi 选择可用的 bfreg
bfregn = alloc_bfreg(dev, &context->bfregi);
// 2. 根据 bfreg 获取 sys_page, 存储 UAR ID
uar_index = bfregn_to_uar_index(dev, &context->bfregi, bfregn, false);
// 3. QP 关联 UAR ID
MLX5_SET(qpc, qpc, uar_page, uar_index);
// 4. 返回关联的索引
resp->bfreg_index = ...;
最后总图
思考
- 在 ibv_open_device 执行过程 Mellanox 实际分配映射了 8 UAR, 16 寄存器, 如果在同一个 ibv_context 调用 ibv_create_qp 超出16次,则会出现复用 BFREG 的情况。