最后更新: 2026-02-25, 作者: HAO022
最近向 Linux 内核社区提交了一个小补丁,目的是希望通过更加通用的方式,定位因网卡驱动,硬件导致的问题(这类问题 dropwatch 不起作用)。内核社区的朋友问到,为什么不采用 ethtool -S。因此才有本篇,分享下因使用 ethtool 导致的线上故障。
问题描述
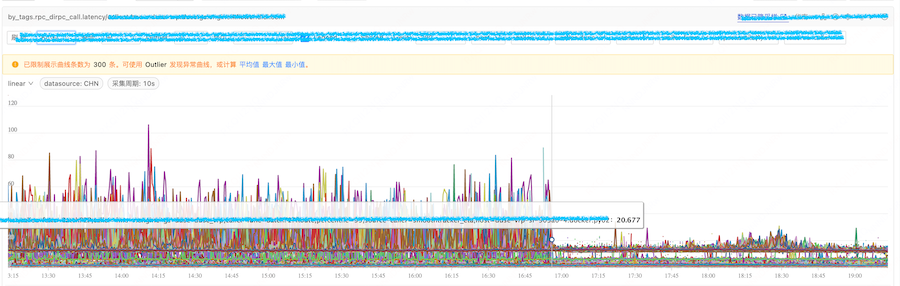
大概在 2024.07.11 11:10,线上某两个服务集群,近乎一半的容器出现 rpc 延迟过高,甚至达到 80ms 延迟。
集群 A:11:10 出现大量延迟
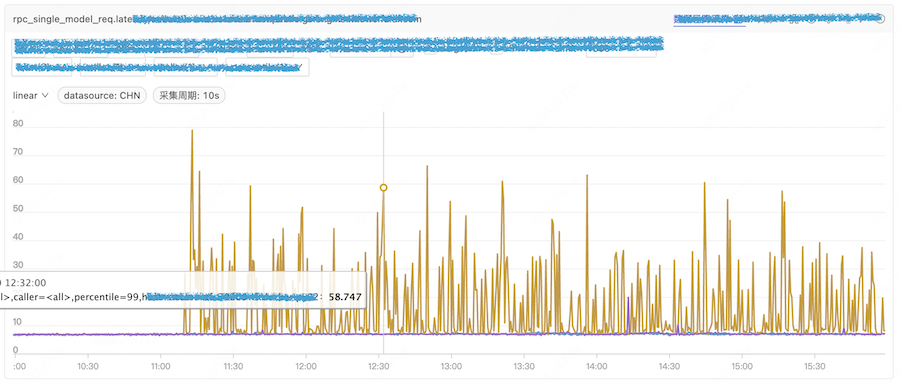
集群 B:延迟如下
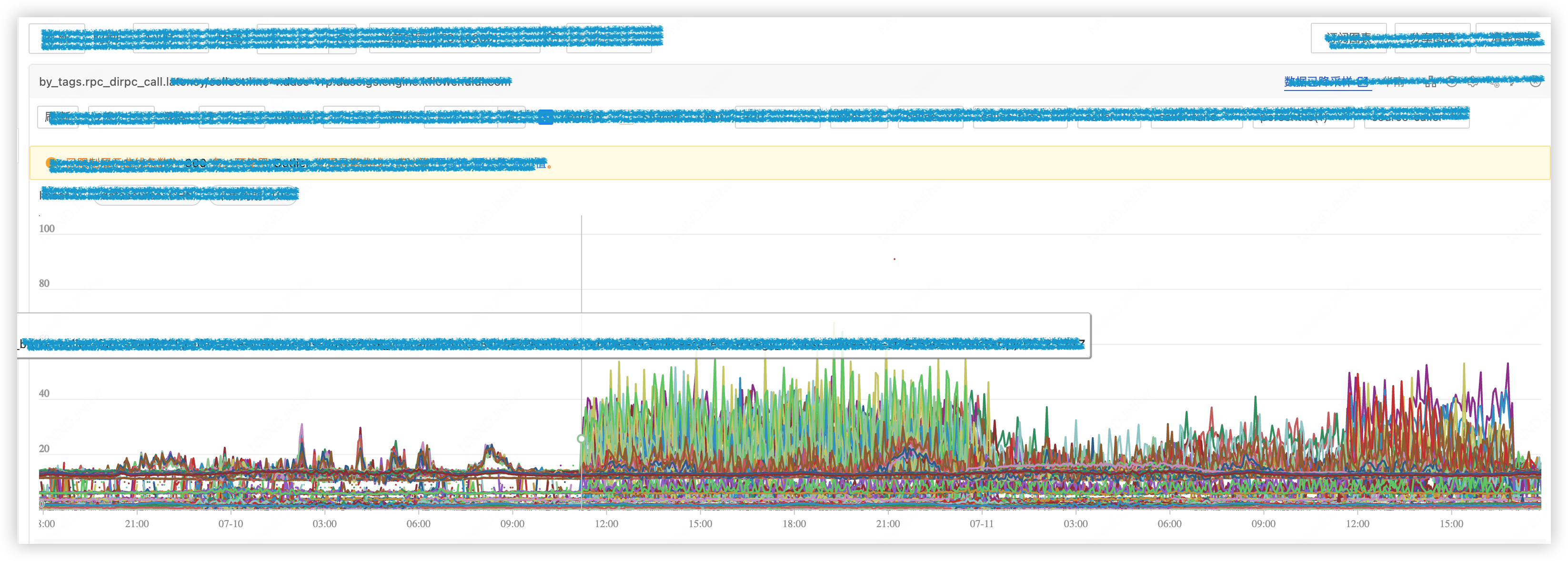
将有问题的容器漂移到没有问题容器所在宿主机,问题解决,业务指标恢复正常,坐实宿主机问题。
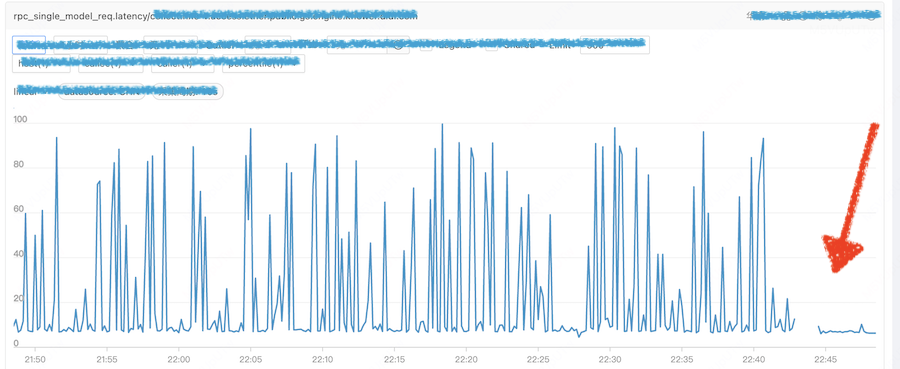
同时,这个问题和特性的事件强相关。通过上线公告发现,11:00 上线一监控组件,因此通过关闭该组件的指标采集,受影响的业务得到了灰度。
问题分析
初因分析
和业务沟通后发现,新的组件通过 ethtool 获取网卡的监控指标。但并非开启该组件采集的宿主机都有问题,统计后发现:有问题宿主机的网卡驱动为:mlx5_core、ixgbe,无问题的宿主机的网卡驱动为:bnxt_en。
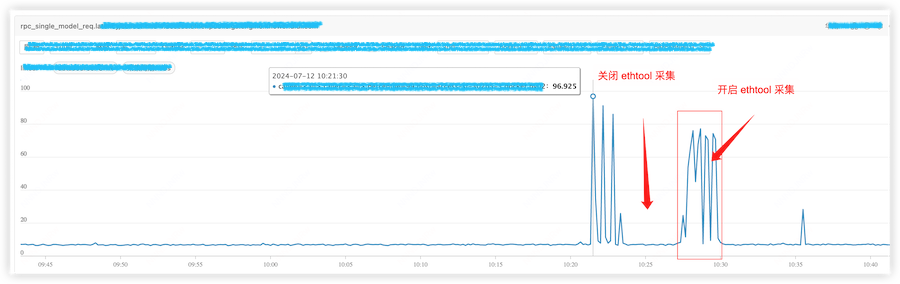
线下复现
围绕 ethtool 内核模块中可能的耗时来源进行耗时统计,以 mlx5e_stats_update() 函数为例,组件通过频繁的查询硬件信息时,会出现接近 100ms 的耗时。而直接通过 ethtool 工具(例如: ethtool -S eth0) 的方式直接查询硬件信息,则不会出现这种情况,耗时稳定在 2ms。将组件中的所有功能都关闭只保留 ethtool 指标后,耗时也稳定在了 2ms 左右。
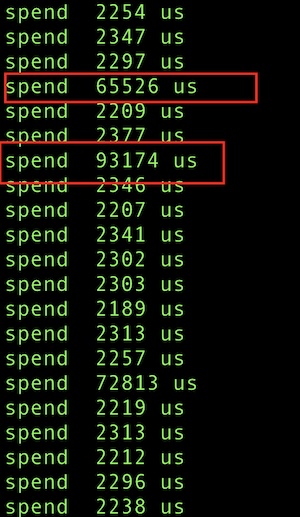
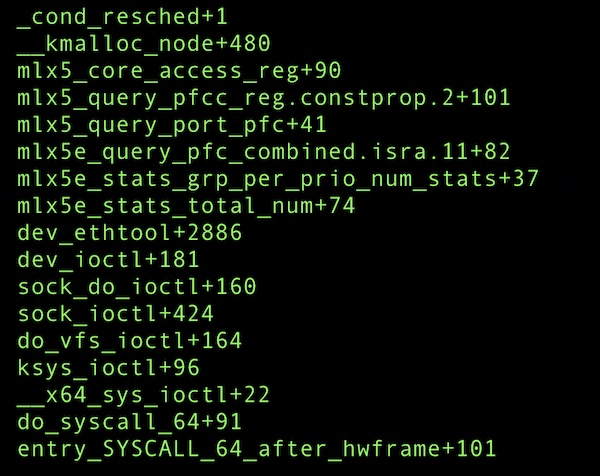
这说明该问题和组件负载也有关联。因此最终通过限制 cgroup 资源,且只有 ethtool 指标的情况下,复现了该问题。如果进程一直被 throttle,内核的某个函数执行耗时增高,那么该函数极大可能执行了 cond_resched 放弃了 CPU。

内核 throttle 只可能发生在 cond_resched(),抓取的部分可能 throttle 的栈信息。
栈1
栈2
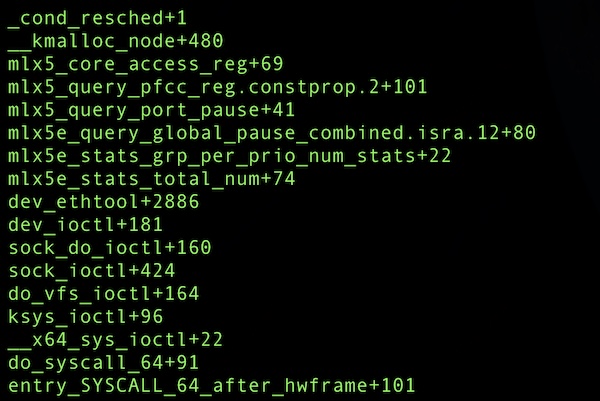
栈3
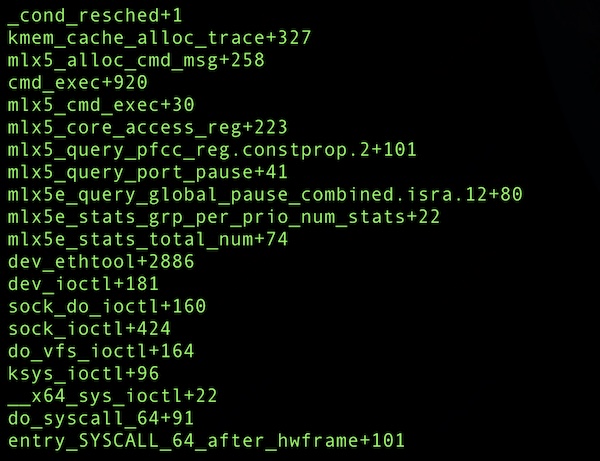
栈4
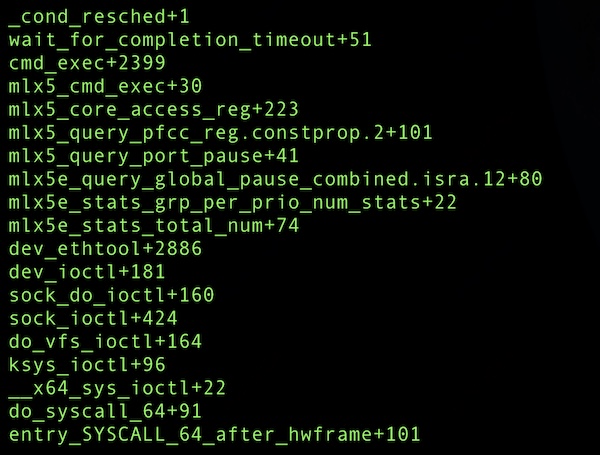
mellanox 驱动执行 cmd_exec(),正常情况下的耗时为 100us,但在高负载情况下执行时长达到 80~100ms(cmd_exec 被 mellanox 驱动用于和硬件交互,获取,配置网卡信息)。 cmd_exec 通过 cond_resched 让出了 CPU,但此时它还持有 rtnl_lock 锁。 很多应用程序会高频的通过netlink获取路由等信息,这和 rtnl_lock 锁存在竞争关系。
线上验证
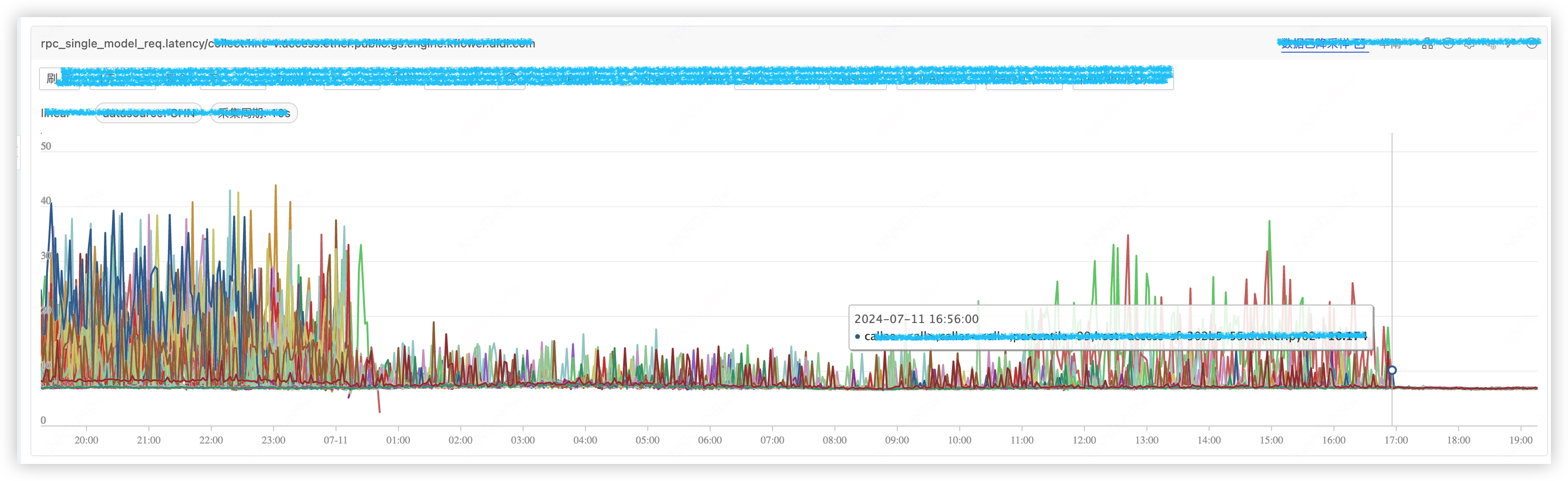
验证分为几个阶段,时间线分别在图中标识。
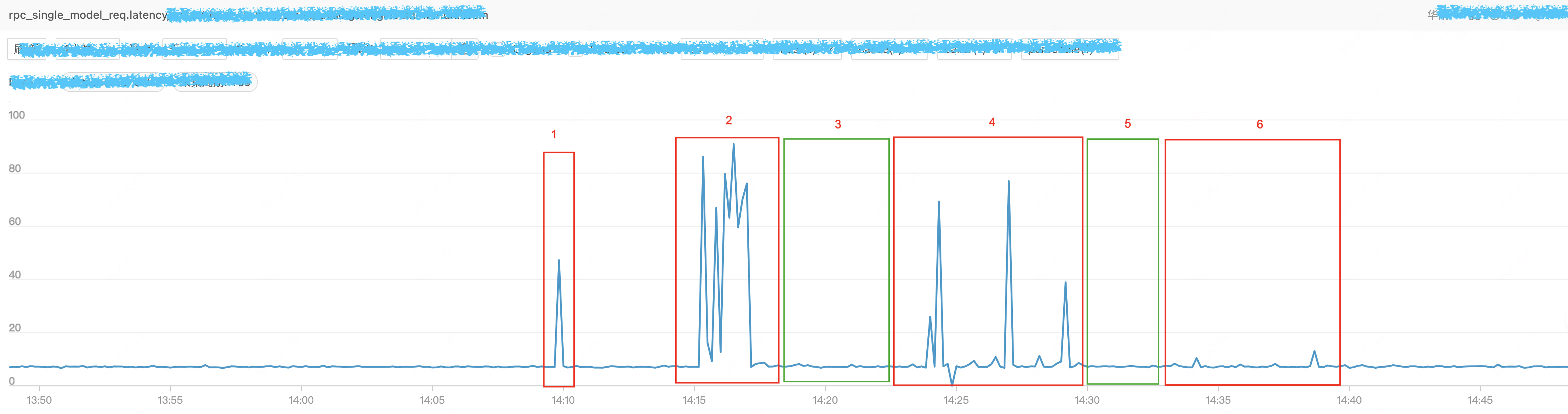
- 阶段1:频繁调用 ethtool 接口,构造出的业务毛刺
- 阶段2:在阶段1的基础上,减小 cgroup cpu 资源,业务毛刺明显增加。
- 阶段3:在阶段1的基础上,增大 cgroup cpu 资源,不产生任何 throttle,业务毛刺消失。
- 阶段4:在阶段1的基础上,降低采集压力,减少 throttle,业务毛刺存在,但不明显。
问题总结
夜深了,为什么还没有睡,如果本篇文章对你有价值,那么不妨在 github 帮我点点 ⭐️
篇尾:
- HUATUO(华佗)是由滴滴开源并依托 CCF 孵化的操作系统深度观测项目。
- 关注微信公众号,或扫码加微信,邀请你加入用户群(请备注姓名+单位):
