
最后更新: 2026-03-15, 作者: 胡洪
HUATUO(华佗)再出手,抓出 504 超时错误元凶!
问题背景
公司业务 A 反馈,在访问服务 B 时出现大量的 504 错误,且大概率在建立连接时出现,而非读写超时。
问题影响
该服务作为核心流量入口,承担着全局流量调度与管控的职责,位于核心链路,一旦批量异常,将导致大范围业务访问中断,潜在风险影响极大。
问题分析
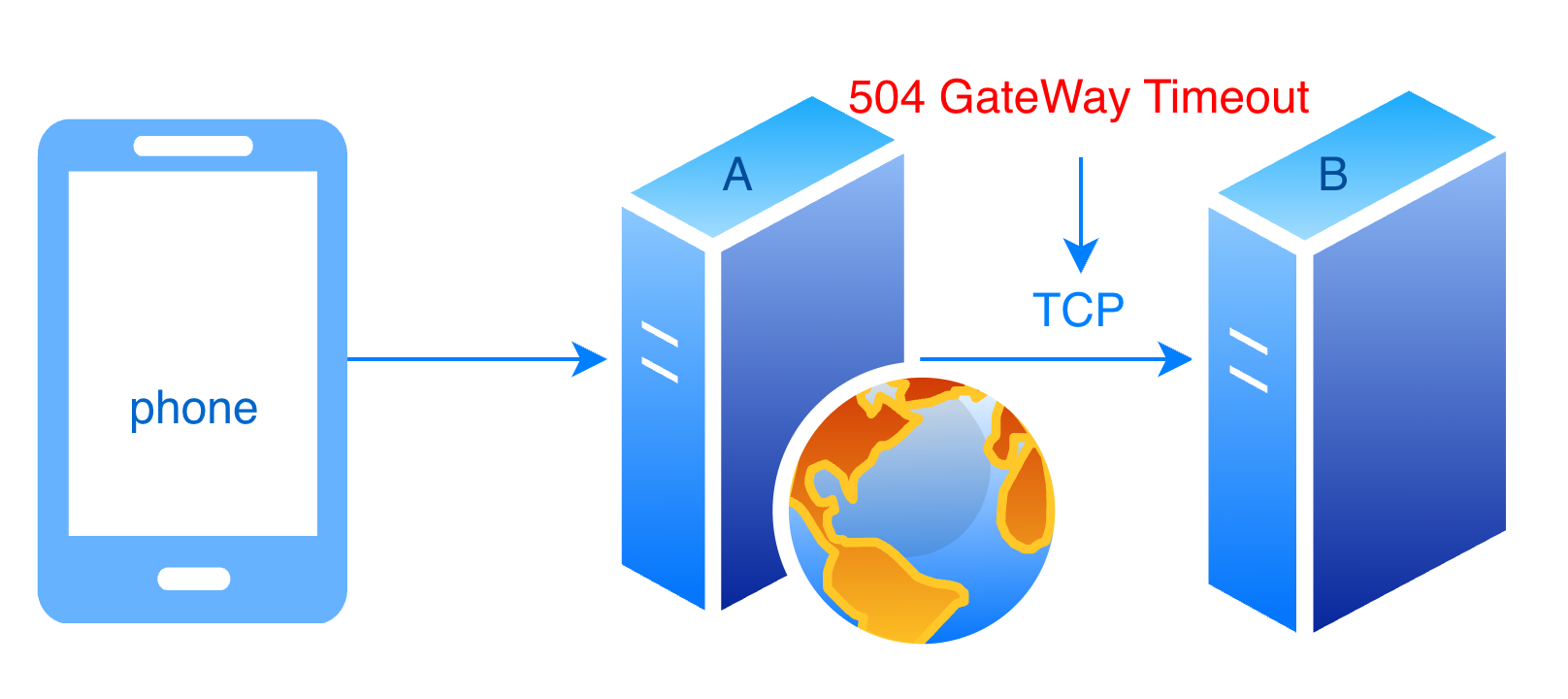
当 A 服务访问 B 服务时,若出现大量建立连接或者传输失败超时,则会返回 504 超时错误。网络架构简图如下:
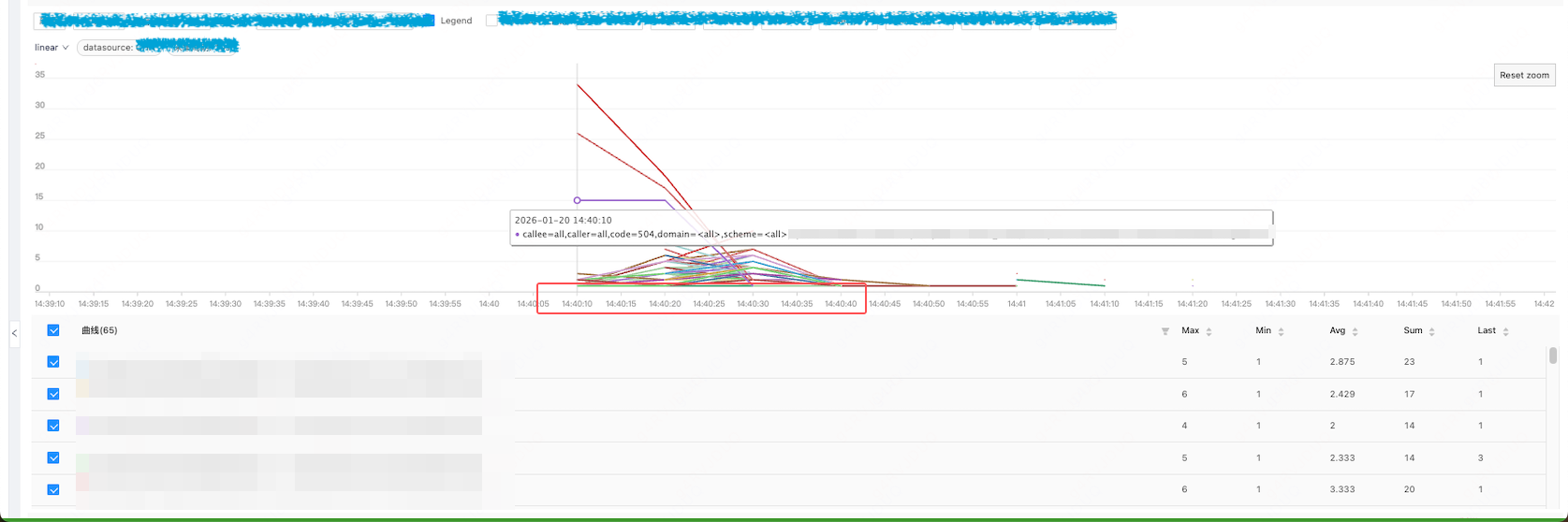
开始问题分析,在 14:40 A 服务访问 B 服务时建连失败,A 服务侧的监控如下:
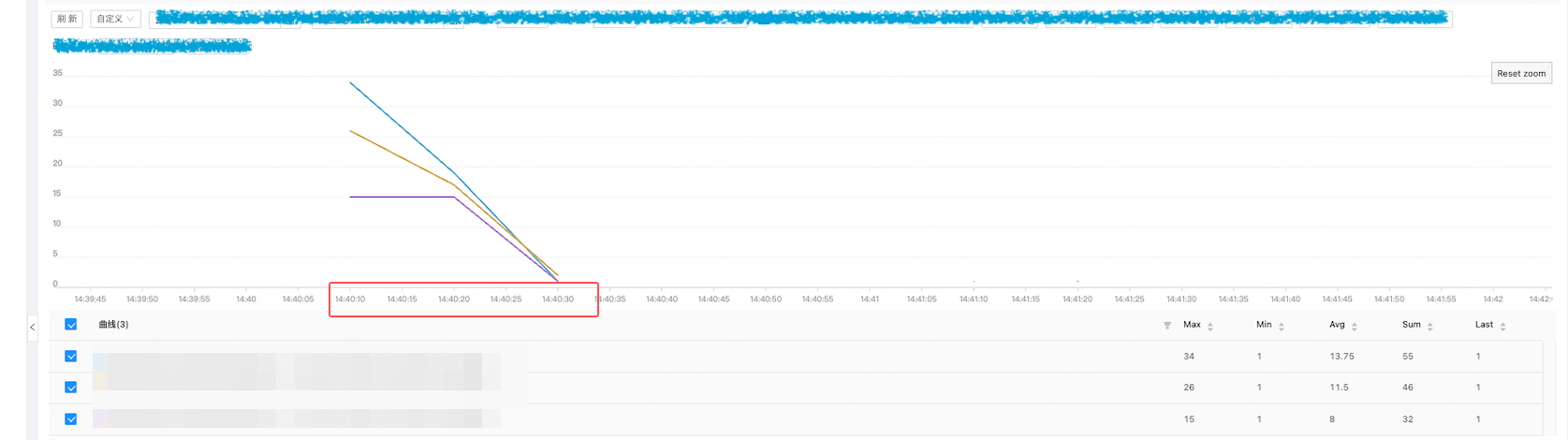
查询出现上述问题的容器,比较巧合,这些容器均在同一台宿主机,那我们就先从单机入手:
祭出大法
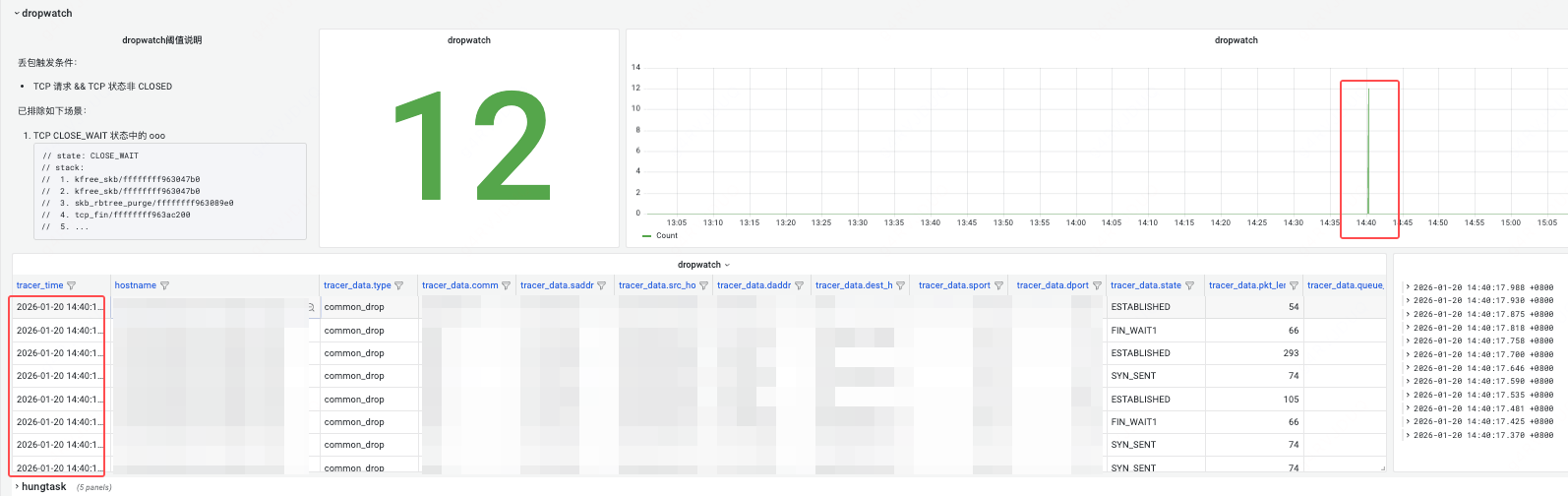
重点来了!为了揭开这 504 背后的神秘面纱,祭出 HUATUO autotracing 大法,通过观察 HUATUO autotracing 大盘,惊奇地发现 HUATUO 在 14:40 抓取到多起宿主机 dropwatch 丢包事件:
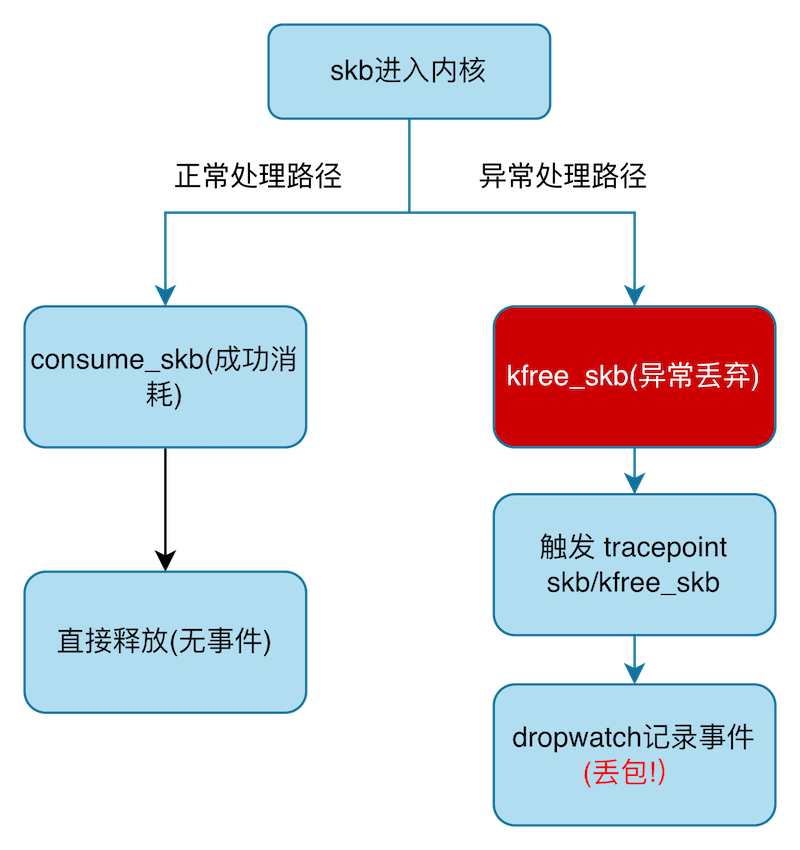
HUATUO dropwatch,是一个基于 eBPF 实现的丢包检测工具,它常态运行实时监控宿主机、容器 TCP 丢包事件。简单说下基础原理,Linux 内核通过如下两种方式释放 skb:
- 包被成功处理 consume_skb
- 包被丢弃 kfree_skb
SEC("tracepoint/skb/kfree_skb")
int bpf_kfree_skb_prog(struct trace_event_raw_kfree_skb *ctx)
因此 dropwatch 通过 kfree_skb tracepoint 获取丢包事件,获取网络信息如 IP,端口,TCP 标记,调用栈,进程信息等。
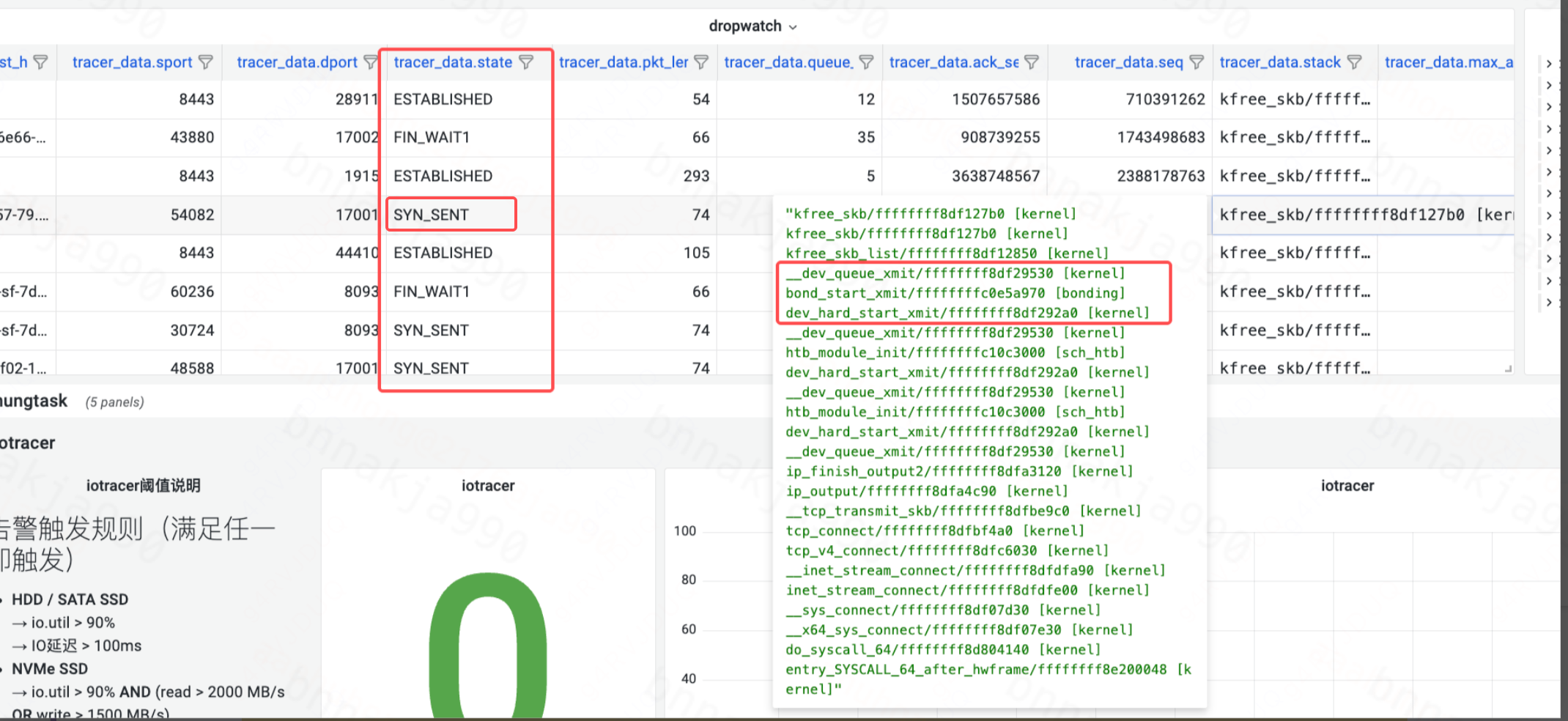
通过 HUATUO 大盘发现,丢包出现在 TCP 建立连接(SYN_SENT、FIN_WAIT1)和数据传输(ESTABLISHED)阶段。从调用栈可见,丢包时的最终调用函数均为上图标红的三个函数,且都是在发送时丢包。
以 SYN_SENT 状态为例,该阶段丢包表明 TCP SYN 包在发送过程中被丢弃。由于内核的 SYN 重传机制通常在约1秒后触发重传,若 nginx proxy_connect_timeout 设置过短(如0.5秒),则会在重传前判定连接超时,直接返回 504 Gateway Timeout。
在 ESTABLISHED 状态进行数据传输时,由于 TCP 具备快速重传机制,数据传输过程中的丢包对业务层影响较小,感知不明显,这与业务侧的实际反馈相符。
再进一步
那么,为什么会丢包?为了便于分析,我们按照协议栈的分层结构,将上述调用栈的执行流程简化为:
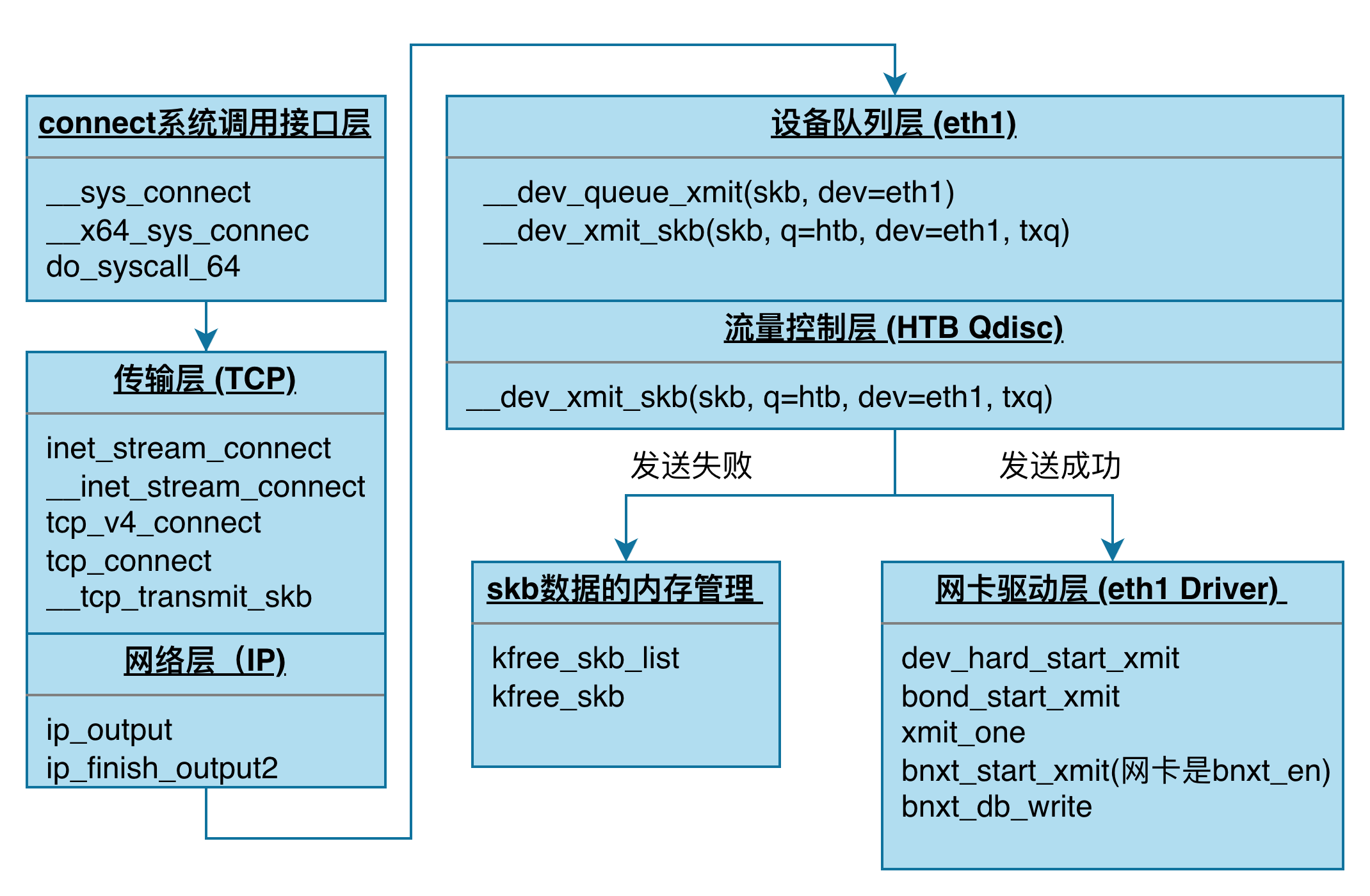
小提示:可依据上图的skb传输流程进行层级映射,结合 dropwatch 捕获的内核丢包调用栈,从而精确定位丢包发生于协议栈的具体环节。
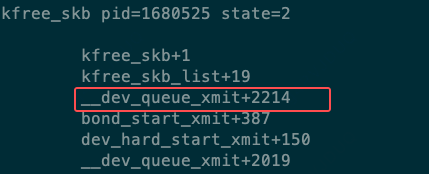
__dev_queue_xmit 在哪里调用了 kfree_skb_list ?用 BPF 脚本获取调用栈信息,此时可知 kfree_skb_list 在 __dev_queue_xmit+2214 位置的上一行。
我们采用 crash 工具,执行下面的反汇编命令:
crash vmlinux
dis -l __dev_queue_xmit
得到 __dev_queue_xmit 函数的汇编指令与其对应的内核源代码行交错显示:

可以看到当时是在net/core/dev.c:3524调用了 kfree_skb_list 函数执行丢包:
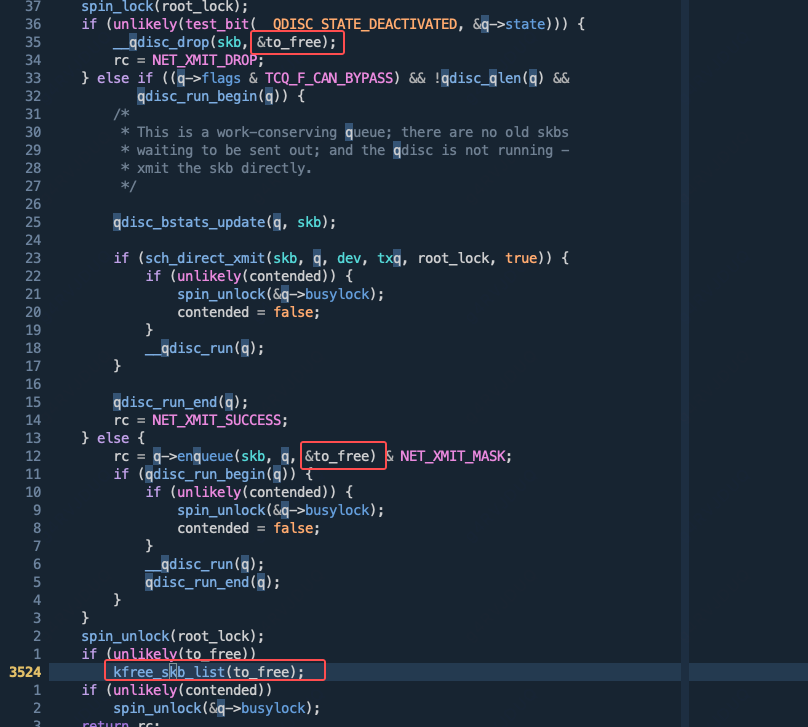
然而,当前存在两个执行路径会将 skb 赋值给 to_free 进行释放。这很可能是由于 qdisc 的状态为 __QDISC_STATE_DEACTIVATED,从而导致丢包。为验证这一推断,我们继续使用以下 BPF 脚本来捕获 kfree_skb 调用时 qdisc 的状态(即 q->state):
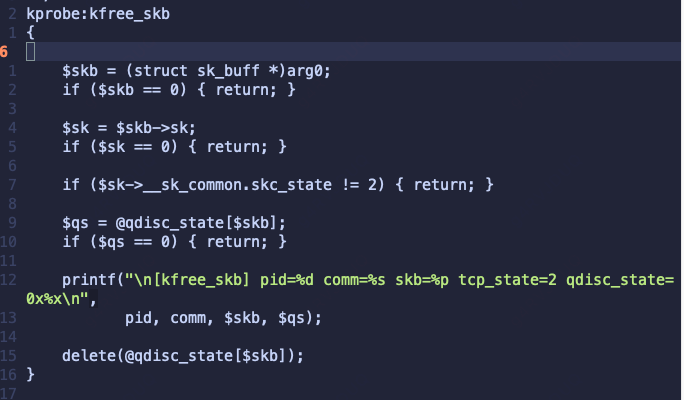
BPF 程序捕获到 qdisc 状态值 q->state 为 2,这表明其 bit 1 已被置位。qdisc 状态为 __QDISC_STATE_DEACTIVATED。
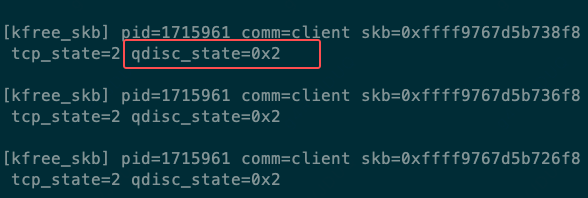
enum qdisc_state_t {
__QDISC_STATE_SCHED,
__QDISC_STATE_DEACTIVATED,
__QDISC_STATE_MISSED,
__QDISC_STATE_DRAINING,
};
Qdisc DEACTIVATED 状态和网卡状态有关,因此查看当时网卡接口状态,HUATUO autotracing 大盘的网卡指标 netdev_events carrier_down,确认在 14:40 网卡链路出现异常,进而导致丢包。
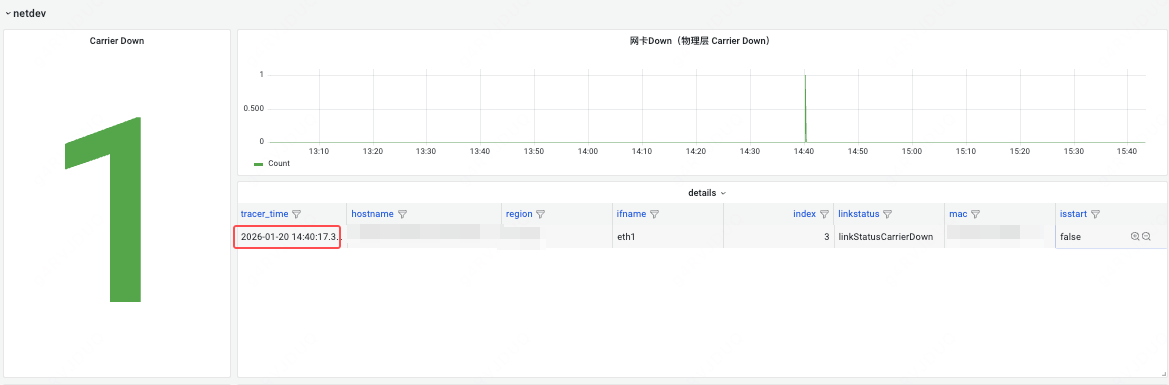
至此,该问题分析的非常清楚,根因就是网卡链路出现问题,而这类异常事件很难被观测到,但 HUATUO(华佗)却很好的支持了这个特性。
最后一击
造成宿主机侧网卡的物理层(carrier)down掉通常有两种情况:
-
光模块/线缆正常,NIC 网卡固件或者硬件问题(netdev_events carrier_down 可感知):
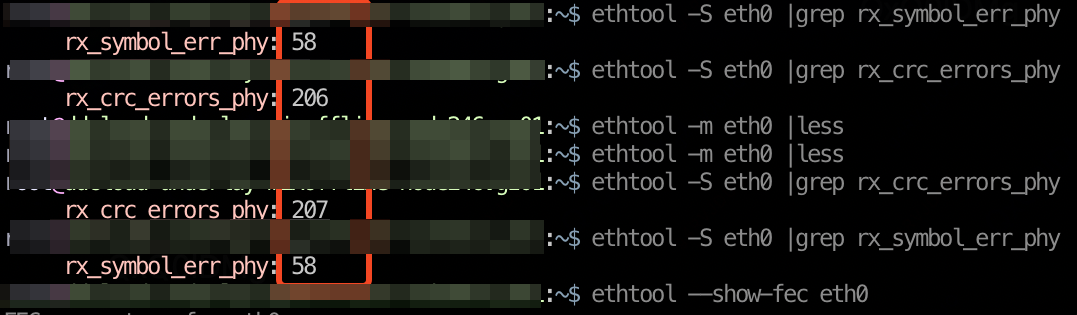
-
光模块/线缆问题(netdev_events carrier_down 可感知),如下图,主要是收光弱导致的网卡偶尔down掉:

线缆、光模块、网卡固件/硬件问题会导致物理机网卡 carrier down,交换机侧的端口 down 也会导致对端物理机网口 carrier down。另外进程/管理员操作也会导致网口 down,但是 admin_down。
- 怎么区分:参考 HUATUO 的 linkstatus_* 指标
- 怎么及时事件通知:参考 HUATUO 的 netdev_events 事件
最后总结
有了 HUATUO 之后,排查故障根因变得前所未有的简单。用好 HUATUO,很多问题都能在第一时间被发现并定位。希望大家在日常运维和开发中,多多尝试、积极使用,让根因定位变得轻松高效。
参考链接
https://github.com/ccfos/huatuo/blob/main/core/events/dropwatch.go https://github.com/ccfos/huatuo/blob/main/core/events/netdev_events.go https://github.com/torvalds/linux https://www.kernel.org/doc/Documentation/networking/operstates.txt
篇尾:
- HUATUO(华佗)是由滴滴开源并依托 CCF 孵化的操作系统深度可观测项目。
- 关注微信公众号,或扫码加微信,邀请你加入用户群(请备注姓名+单位):
