
最后更新: 2026-03-15, 作者: 王洪磊
问题背景
某独立集群的多个服务反馈,运行在 AMD 机器上的容器偶发出现较大的耗时毛刺。以如下服务为例,19号容器运行在 AMD 机器上,1号容器运行在Intel机器上。
初步分析,部分原因在于 AMD 机器上容器部署密度较高,导致日志数据采集程序突发新建进程量变大很多,对业务容器进程造成影响。这种影响在高峰期尤为显著。对采集程序调整容器的资源规格后,问题得到一定缓解,但业务团队仍反馈,在非高峰期 AMD 机器上还存在较大的耗时长尾问题。
问题影响
该集群的服务集中部署在独立机房,影响较为集中。同时,报告类似问题的服务数量较多,涉及数百个业务容器。
问题分析
下面详细解释一下调优手段的诞生过程,同时配有详细的线上验证效果。
现象差异
问题涉及多个业务线,并在多台物理机出现。我们以耗时较为敏感的业务 A 的容器为研究对象,选取在 AMD 机器耗时长尾显著的 19 号容器进行分析问题,并以 Intel 机器上的 0 号容器作为对照组:
业务A-0b687-19 amd
业务A-0b687-0 intel
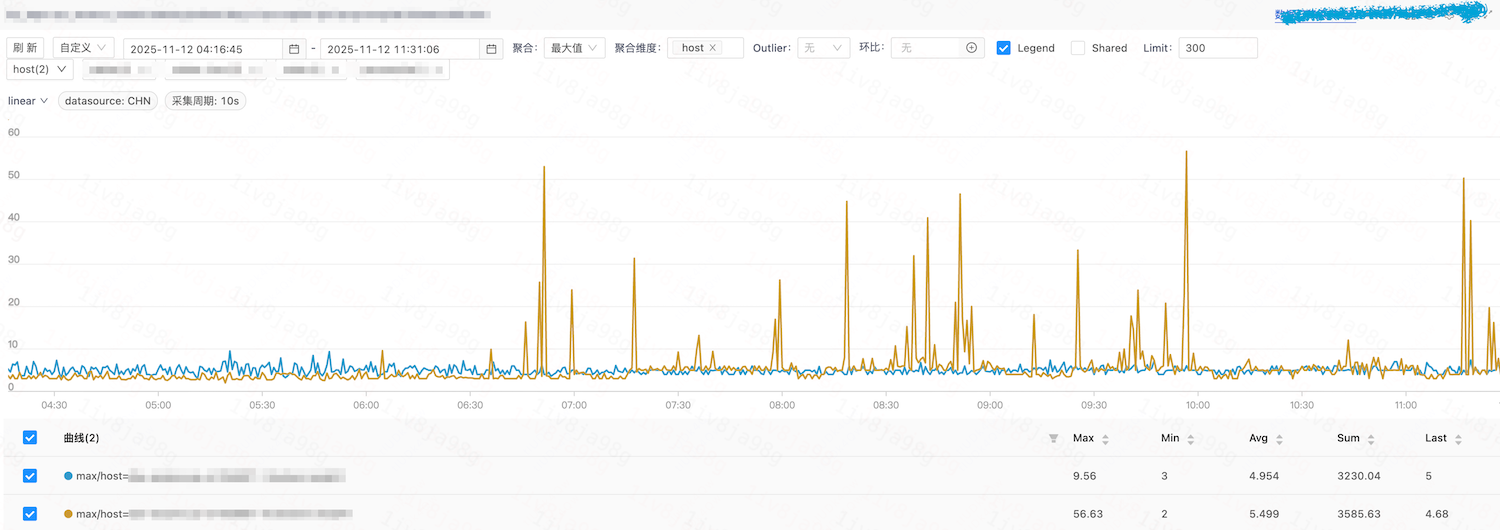
耗时对比如下:0号容器(蓝色曲线)虽然也存在偶发的耗时毛刺,但19号容器(黄色曲线)整体表现更频繁和显著的毛刺现象。
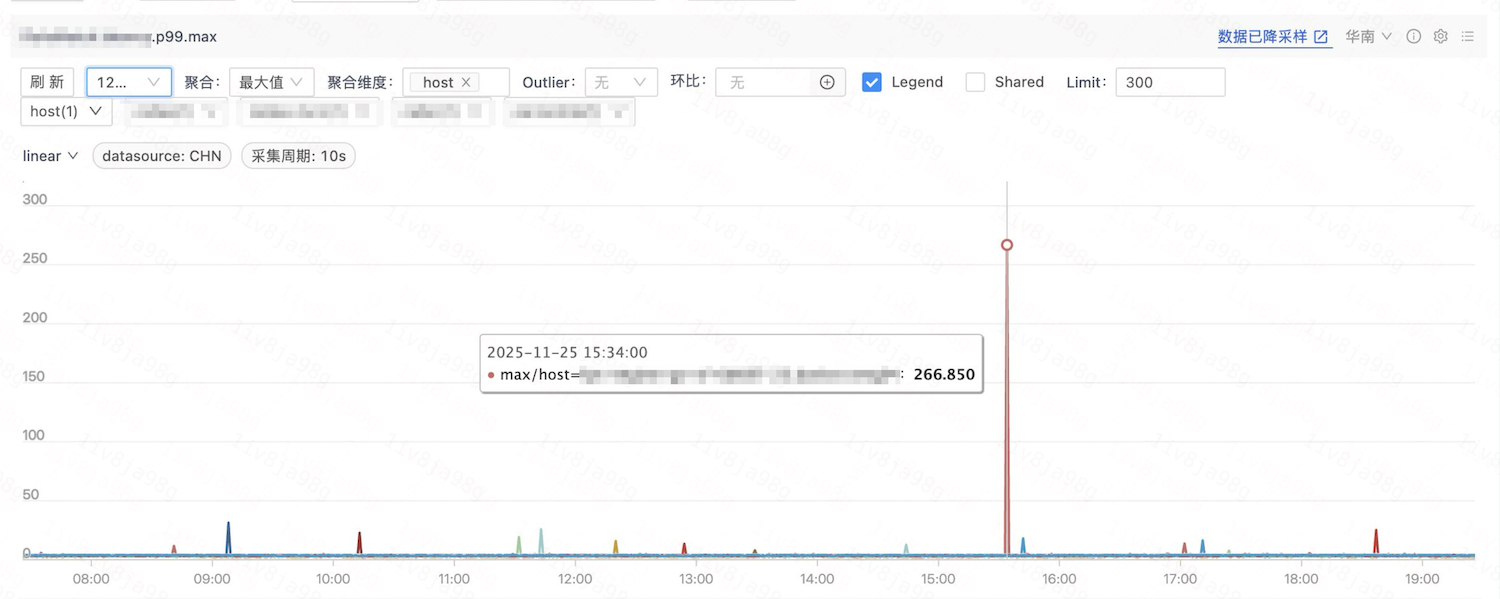
该服务与上下游服务交互较少,其耗时主要取决于CPU计算。通过观察CPU相关指标,发现两个容器在内部争抢上存在显著差异:
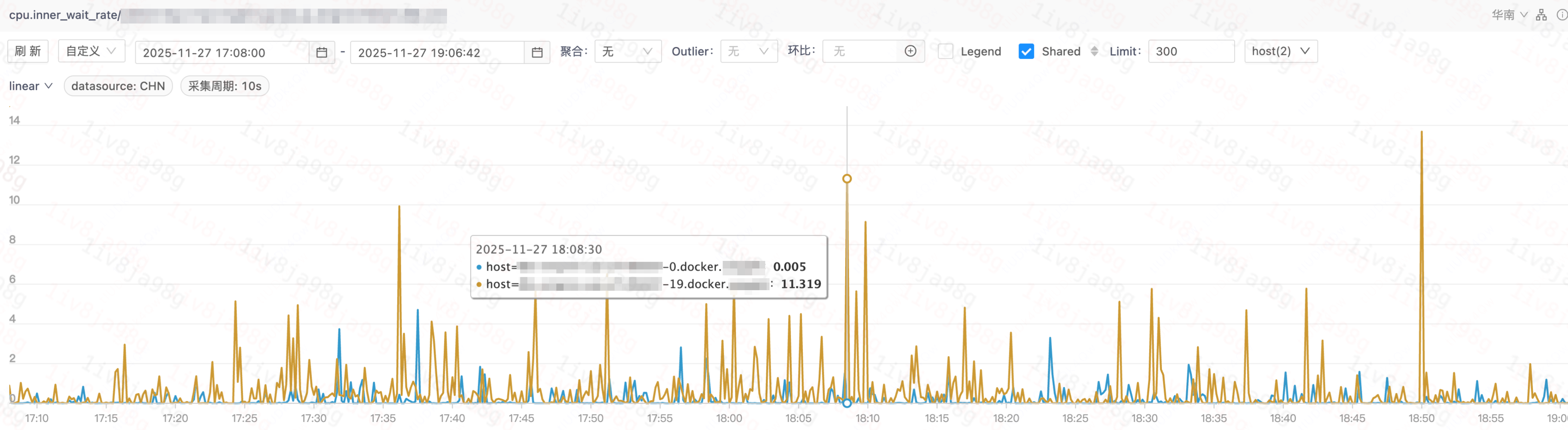
内部争抢指标反映了容器内进程间相互等待的强度。据此可以推测,造成P99长尾耗时的进程很可能是在等待容器内部其他进程。在业务代码和流量完全一致的条件下,为何两种机器在内部争抢指标上表现不同?为何进程会在同一调度队列内相互等待?这需要深入分析内核的CPU选核策略。
选核策略
基于 select_task_rq_fair() 处理流程以及本次问题,总结如下:
-
判断本次唤醒任务的工作模式是否属于want_affine类型。wake_wide()是该特性的核心机制,旨在解决早期内核中出现的关联线程过度集中于同一CPU的问题。作为一种启发式判断算法,它能有效避免server/client等互相反复唤醒场景下任务在调度队列中的无效排队。但当前的业务模型并不属于此类情况。
-
以当前 cpu 为起点,逐级向上遍历调度域,并在首个同时包含当前 cpu 和 prev cpu 的调度域中,尝试通过 wake_affine() 选取目标 CPU。wake_affine() 主要采用两种选择策略:WA_IDLE、WA_WEIGHT。
WA_IDLE 1. 为了实现更好的 cache hot,新唤醒的任务优先选择之前运行过的 CPU(prev cpu)作为调度目标,以利用其缓存热效应。所以,当 prev cpu 为 idle 的时候,它将被选择为目标 cpu。 2. 若 prev cpu 不处于 idle 状态,且当前执行唤醒操作的 CPU 与 prev cpu 共享LLC,同时满足同步唤醒(sync)条件且当前 cpu 即将进入 idle 状态,则当前 cpu 可作为目标CPU。 WA_WEIGHT 若WA_IDLE策略未能成功选出目标 CPU,则通过比较 prev CPU 与当前 CPU 的负载情况来选择目标 CPU。上述两种策略均未能选出合适的CPU,则将 prev CPU 作为目标 CPU 返回。
-
内核会在目标 CPU所属的LLC域内尝试寻找 idle CPU(参见select_idle_sibling())。在此过程中,系统仍会优先考虑 cache hot。若未找到 idle CPU,则prev CPU将成为最可能的备选方案。
-
经历了前面的步骤后,任务可能被放入的CPU可能是 prev、current、或者两者所在 LLC 范围内的某一个 idle CPU。
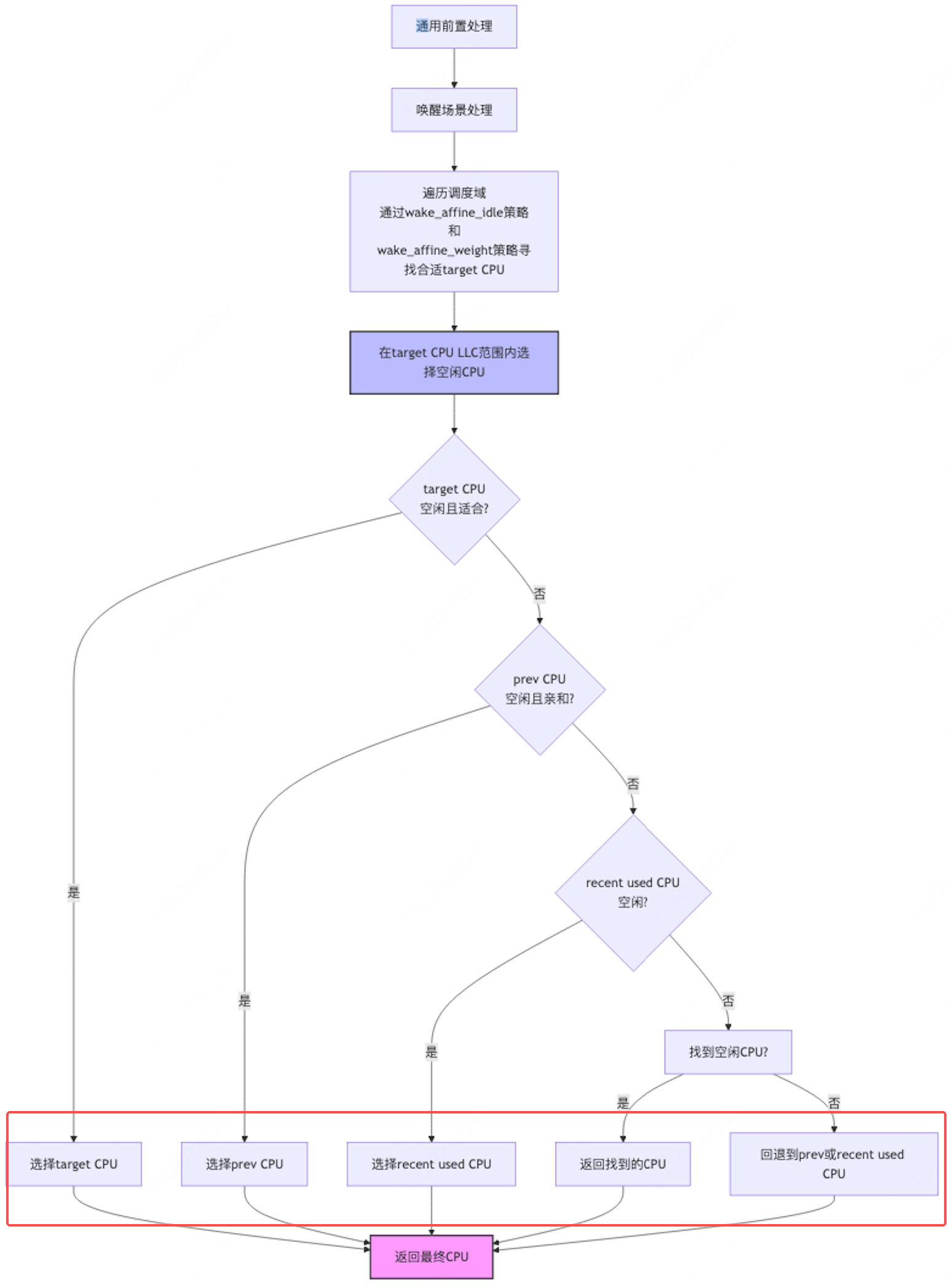
基于上述流程分析,新唤醒的任务很可能保留在之前运行过的CPU所属的 LLC 域内。即使该域内已无空闲CPU,出于缓存热效应原则,任务将进入调度队列等待。
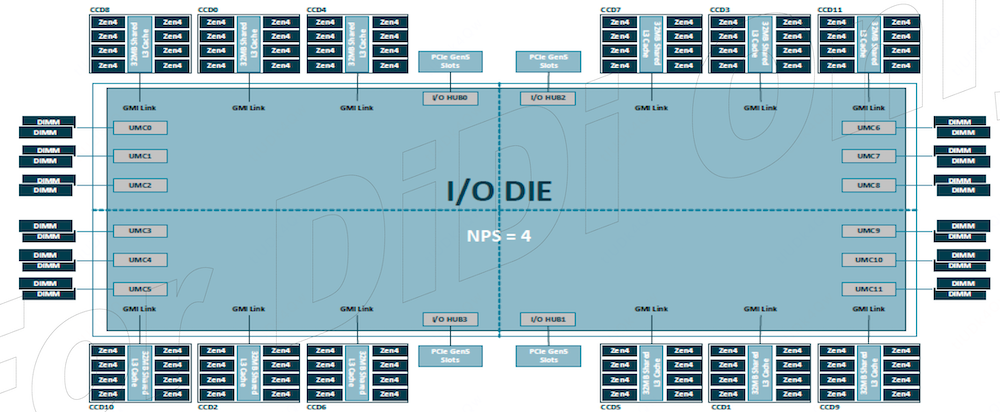
进一步,AMD 与 Intel CPU 在芯片LLC 差异比较明显。 Intel CPU 同一物理芯片的所有核心共享 LLC。例如某个物理芯片包含24个核心,开启超线程后呈现为 48 逻辑核心,这些核心共享 LLC。 AMD CPU 为 单 DIE、多 CCD 架构。Genoa 为例,单个 DIE 包含 12 个 CCD,每个 CCD 集成 8 个核心,开启超线程后,呈现为16个逻辑核心,这些逻辑核心共享 LLC。
在单个业务容器中,通常只存在一个主工作进程,整个容器以单一 task_group 作为组调度单元。基于 cache hot 和进程间唤醒关系,这些进程(现成)通常喜欢“在一起”工作,也就是倾向于集中运行在同一个LLC域内,新唤醒的任务将更容易被调度至相同的LLC。
调优方法
鉴于AMD架构的特殊性,同一个容器的任务更容易“挤在”一起后,这是否意味着任务将始终在资源受限的条件下运行?事实并非完全如此。
这涉及到调度器的另一个关键机制——负载均衡。最常见的内核负载均衡发生在某一个 cpu 即将进入 idle 状态时,此时它会尝试从其他繁忙 CPU 上迁移任务到本地执行,也就是通常所说的 new idle balance。对于“繁忙”的判定涉及load weight、util等多种因素,此处不展开讨论。感兴趣的朋友可以自行深入研究,或待后续我们专题讲解。目前只需理解 new idle balance 会尝试从繁忙CPU上拉任务即可。
负载均衡过程也会考量LLC的影响,但当某个调度域明显过载时,系统允许跨LLC域拉取任务。这为AMD架构中集中在单个CCD内的任务提供了调度到其他CCD运行的机会。以下以问题环境使用的5.10内核为例进行说明(upstream已对相关逻辑和函数名进行调整,此处仅针对该版本):
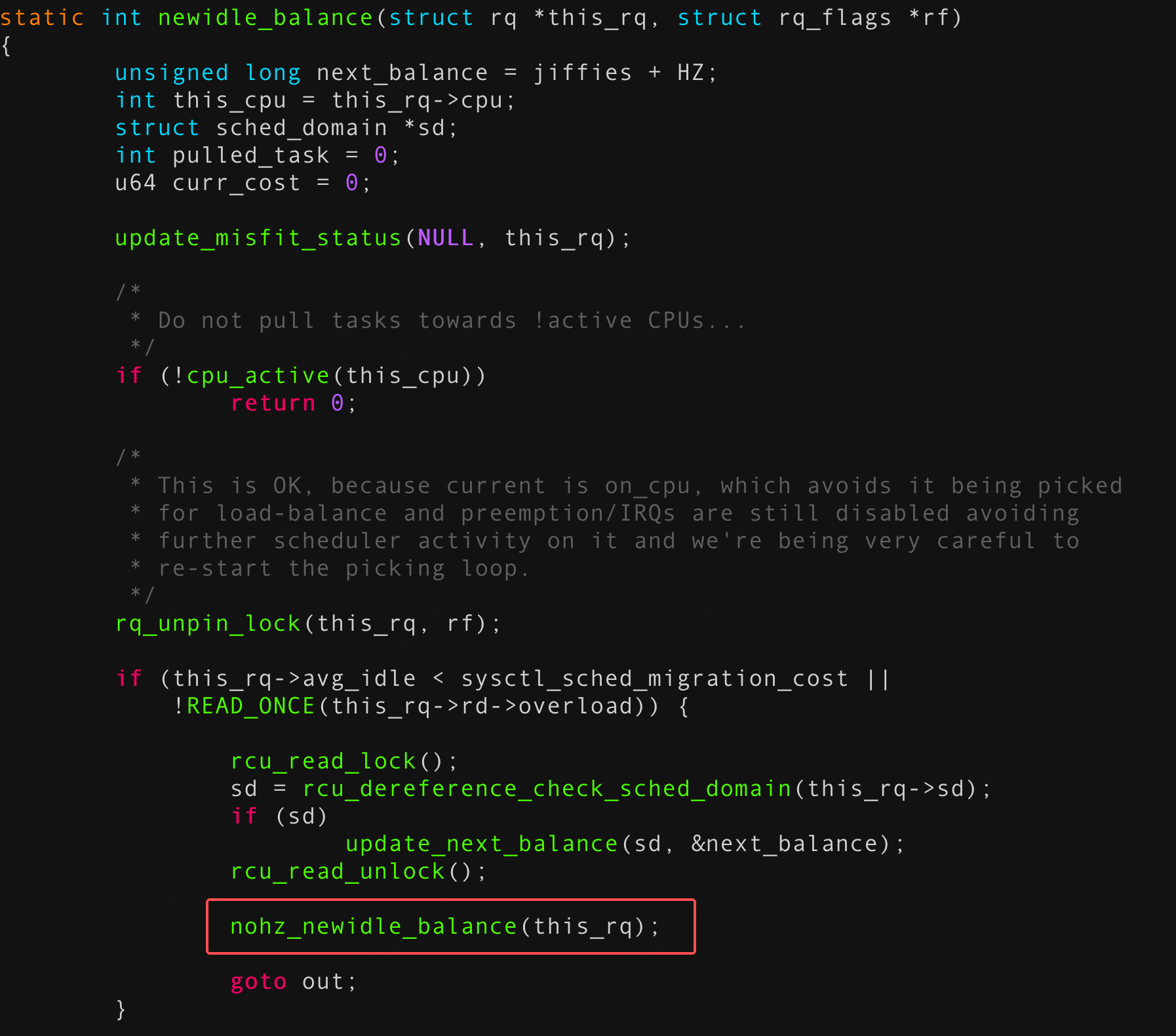
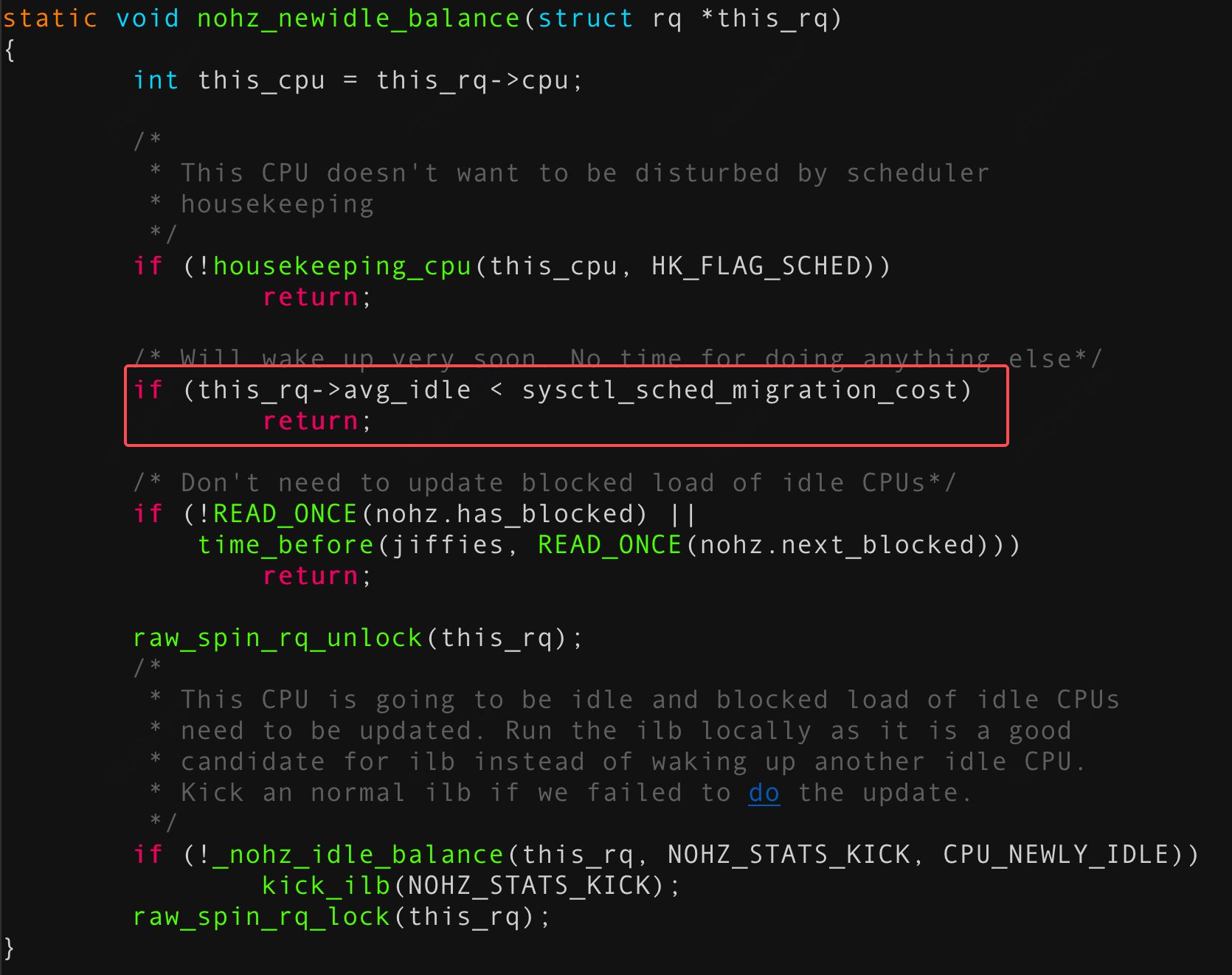
在本问题场景中,关键路径为 nohz_newidle_balance()。在某个CPU即将进入 idle 状态时,需评估自身是否适合从其他CPU拉取任务。评估过程中会检查 rq->avg_idle——其底层逻辑是:若预期空闲时间较短,表明该CPU很快将处理自身任务,此时不宜再从其他CPU拉取任务。具体评估标准为比较 this_rq->avg_idle 与 sysctl_sched_migration_cost。后者表示系统预估的任务迁移时间成本,用于权衡负载均衡的收益。
这样判断此时拉取任务是否"划算":若 this_rq->avg_idle 大于 sysctl_sched_migration_cost,则说明预期的空闲时间足够承担任务迁移开销,此时执行负载均衡是值得的;否则说明空闲窗口过短,不如直接等待后续本地任务调度。
回到当前工作场景,鉴于观察到AMD平台内部竞争指标显著偏高,有理由怀疑 业务 A 容器内的任务“挤在”一起,且未被其他 idle CPU 有效分单负载。基于此推测,若我们适当调低 sysctl_sched_migration_cost 这个经验阈值,提升 new idle balance 机制的触发概率,就有可能缓解这种争抢情况。
线上验证效果
线上 AMD 机器上的 sysctl_sched_migration_cost=5000000,即5ms。

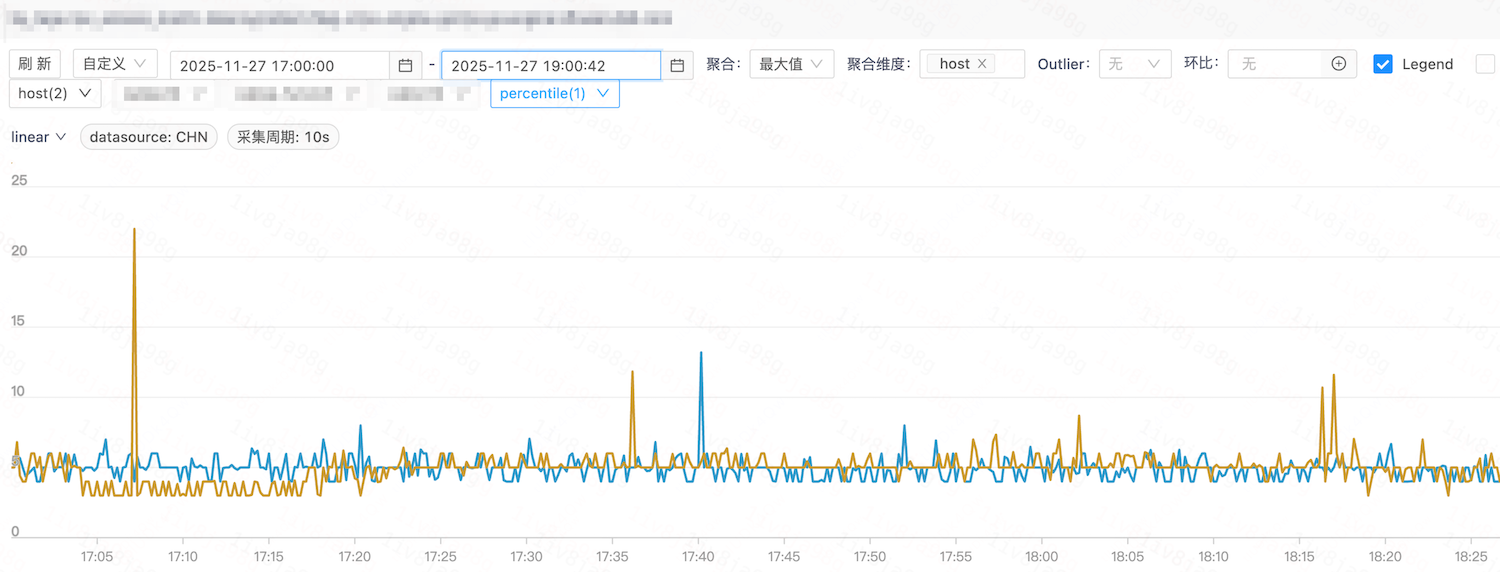
分别选取受影响的服务 A 19 号容器及服务B 7 号容器所在宿主,做参数优化。以下环比截图,其中绿色线为优化后效果。
服务A: 内部争抢指标环比
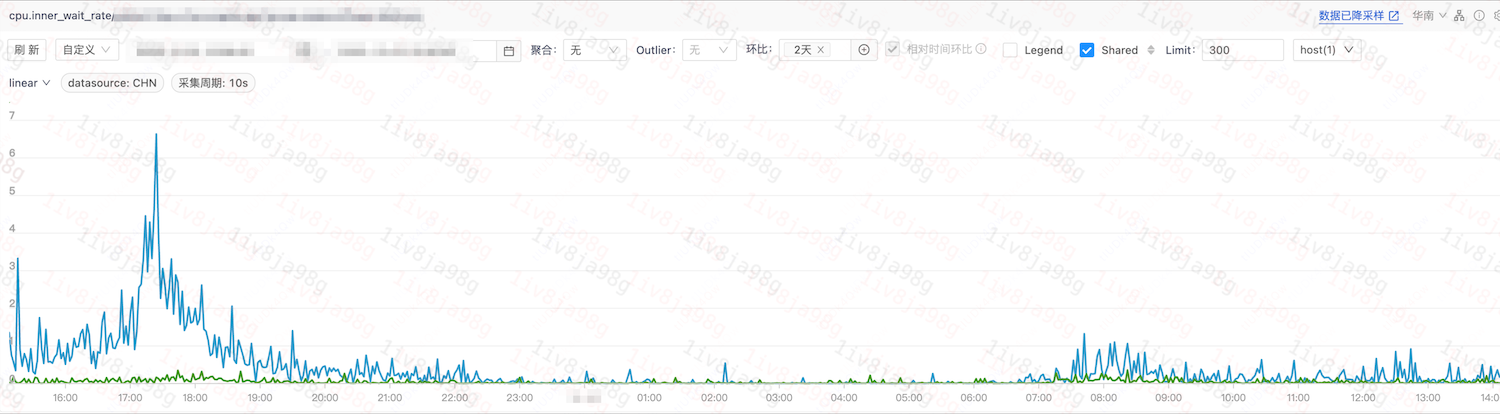
业务P99
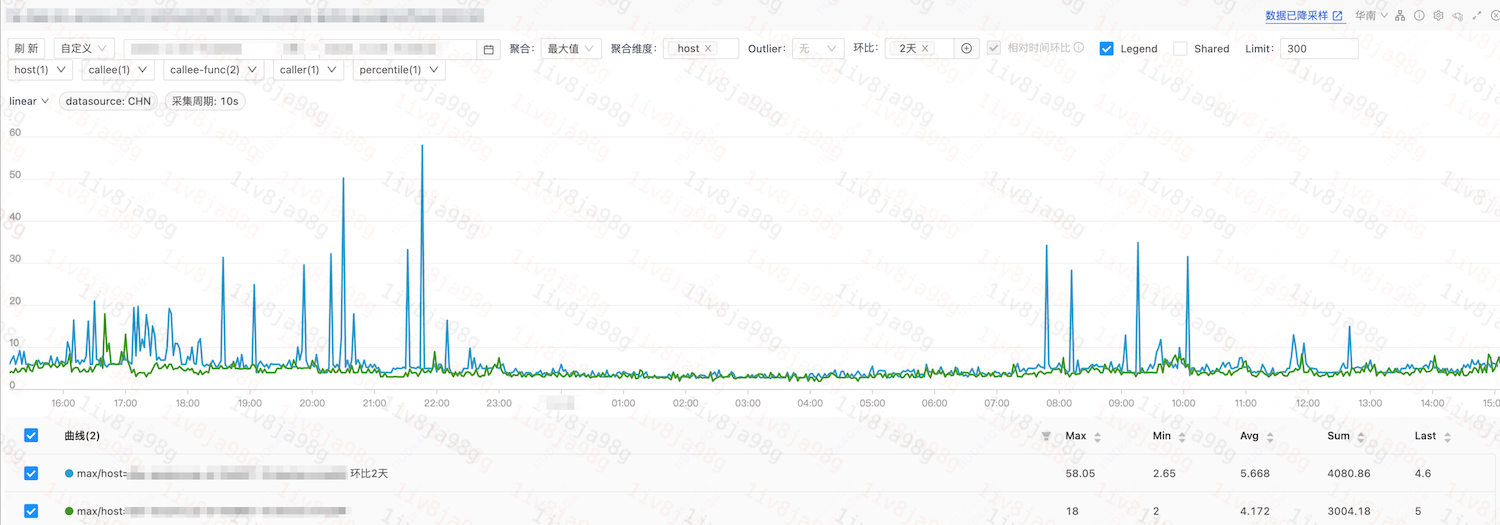
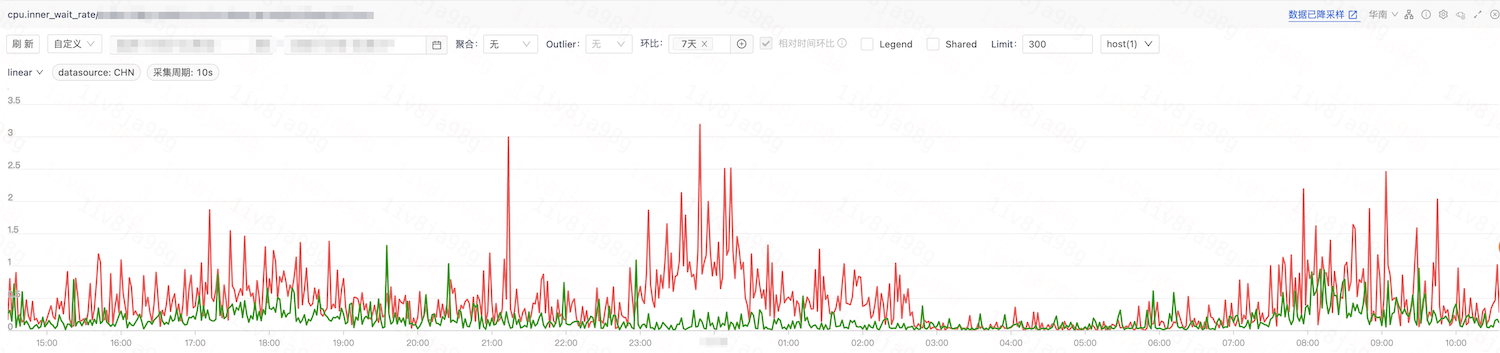
服务 B:
内部争抢指标环比
业务P99
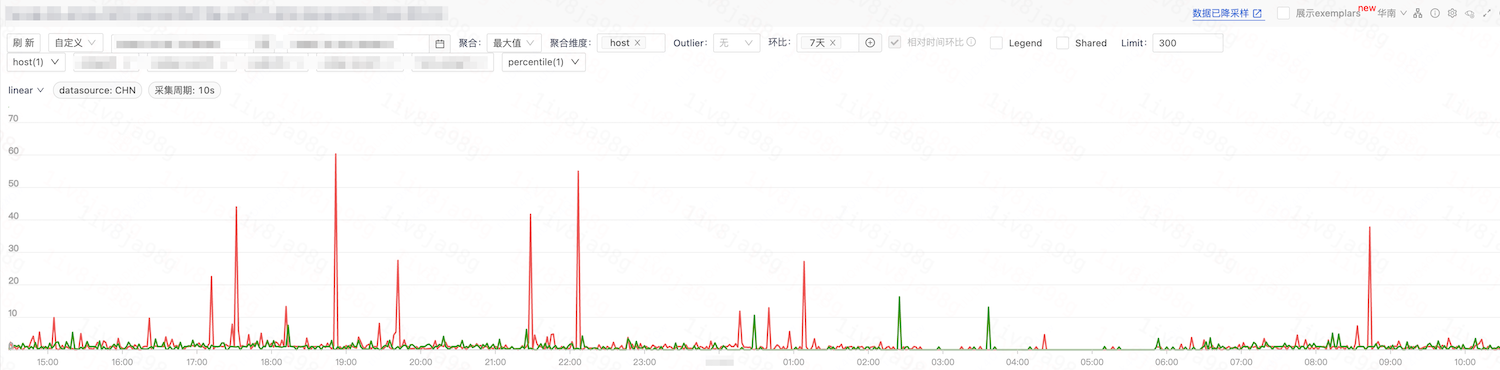
优化结论
针对 AMD 机器,优化 kernel.sched_migration_cost_ns 内核参数有效的将进程平铺到所有 CCD,进而解决业务毛刺问题。
篇尾:
- HUATUO(华佗)是由滴滴开源并依托 CCF 孵化的操作系统深度可观测项目。
- 关注微信公众号,或扫码加微信,邀请你加入用户群(请备注姓名+单位):
