
最后更新: 2026-03-15, 作者: 戴坤海
本篇重点介绍 HUATUO 强悍的 IO 全栈观测能力,实现原理以及故障定位案例。
用户痛点
磁盘被打爆,却找不到罪魁祸首。深夜,监控系统突然报警: 磁盘 IOPS 爆表,磁盘利用率达到 100%!业务响应超时 …
紧急登录服务器,使用各种 IO 工具,试图找出元凶,却:
- 能看到某个进程在触发 IO 操作,却不知道它具体在读写哪个文件
- 能看到磁盘在疯狂写入,却不知道这些 IO 来自哪个业务进程
- 能看到内核线程在刷脏页,却根本无法追踪到原始的业务进程
- 能看到 IO 吞吐量,却不知道这些 IO 的延迟情况,无法定位性能瓶颈
不能全景的分析 “是谁在写”、“写到哪里”、“为什么慢”。排查陷入僵局,业务继续受影响…
解决方案
iotracing 来了!这是一款基于 eBPF 技术的 IO 追踪工具,能够让你一步到位找到高 IO 的所有信息:
- IO 属于哪个进程,支持 PID 和进程名
- IO 属于哪个容器,支持容器化环境
- IO 写到哪个磁盘,支持设备号
- IO 写到哪个文件,支持完整文件路径和 inode 号
- IO 延迟分析,支持 q2c、d2c 延迟,找出性能瓶颈
- 刷脏回写追踪,即使内核线程刷脏页,也能追溯到原始进程
- 高延迟调用栈,捕获超过阈值的 IO,显示完整内核调用栈
基础用法
1. 快速上手
$ iotracing --duration 10
PID COMMAND FS_READ FS_WRITE DISK_READ DISK_WRITE FILES
======= ==================== ======= ======== ========= ========== =====
12345 mysql 5.2GB 1.8GB 6.1GB 2.2GB 128
67890 nginx 2.1GB 890MB 2.3GB 950MB 45
11223 java-app 1.5GB 3.2GB 1.8GB 3.5GB 256
...
输出进程按照磁盘IO量排序,mysql 进程是最大的 IO 消耗者,每秒读取 5.2GB、写入 1.8GB!
2. 深入分析
此外,该工具还会输出读写文件信息:
===========================================================================
PID: 12345 TOTAL_IO: R=5.2GB W=1.8GB FILES: 128
COMMAND: /usr/sbin/mysqld
-----------------------------------
DEVICE FS_READ FS_WRITE DISK_READ DISK_WRITE LATENCY(μs) FILE/INODE
[8:0] 512MB 256MB 512MB 256MB q2c=450 d2c=300 /var/lib/mysql/ibdata1 (1234567)
[8:0] 480MB 240MB 480MB 240MB q2c=420 d2c=250 /var/lib/mysql/ib_logfile0 (1234568)
[8:0] 256MB 128MB 256MB 128MB q2c=480 d2c=350 /var/lib/mysql/test/table1.ibd (1234569)
这里展示了进程操作的文件,可以看到 MySQL 正在疯狂读写 ibdata1、 ib_logfile0、table1.ibd。延迟 q2c,d2c 信息一目了然。
3. 容器环境
识别 IO 来自哪个容器。在容器环境,iotracing 还能显示容器信息 container_hostname :
$ iotracing --duration 10 --json | jq
{
"process_io_data": [
{
"pid": 12345,
"comm": "java-app",
"container_hostname": "order-service-7d9f8b4c5-x2k3p",
"fs_read": 1073741824,
"fs_write": 3221225472,
"disk_read": 1200000000,
"disk_write": 3500000000,
"file_count": 256
}
]
}
4. 回写 IO 追踪
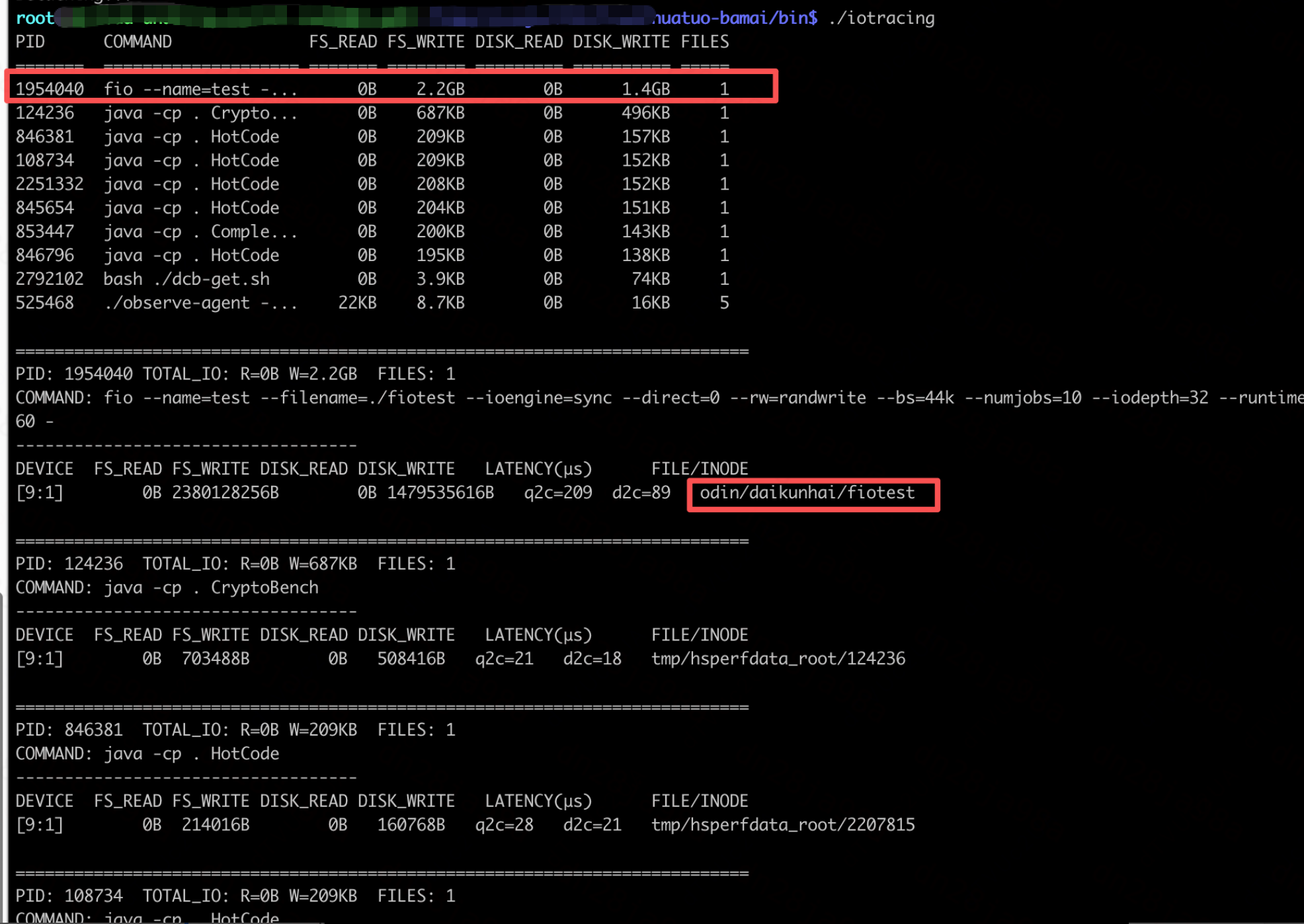
普通的工具只能抓到一堆内核线程kworker在刷脏页,无法定位到io具体来源的业务进程。
iotracing 不仅准确识别到回写io的来源进程,更是精准定位到了io所属的文件。
高级用法
你一定遇到过这样的场景:
- 凌晨监控告警:某台服务器磁盘 IO 突然飙升到 100%,持续 30 秒后自动恢复
- 业务影响:这 30 秒内,数据库查询超时,用户请求失败率飙升
- 排查困境:等你收到告警并登录服务器时,IO 已经恢复正常了。你不知道刚才发生了什么,更不知道如何复现
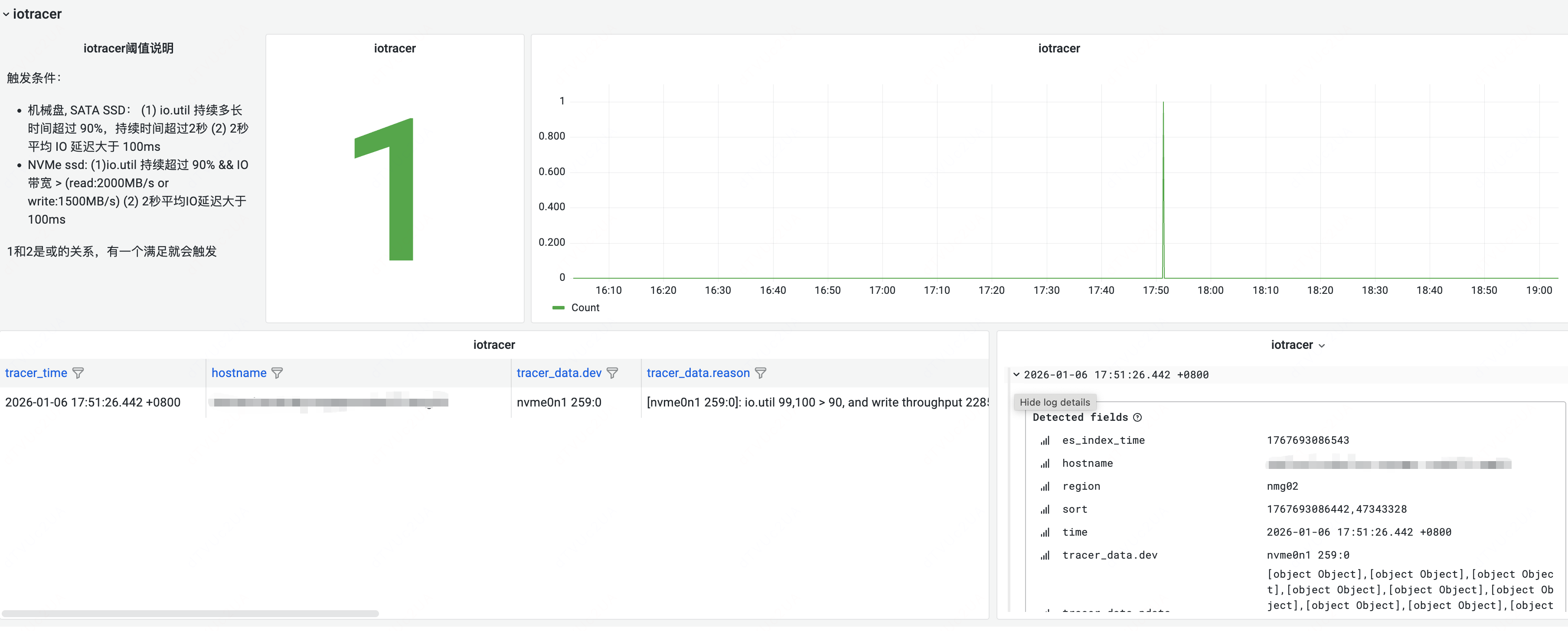
这是典型的突发 IO 问题:突发大量的 IO 请求,持续时间短,但影响严重!HUATUO autotracing 框架搭配 iotracing 可以实时监控的 IO 负载,当出现异常突增或者延迟异常时,会自动调用 iotracing 抓取磁盘快照,以供后续的问题根因分析。
生产环境案例
下面以一个真实的案例来看 iotracing 在服务器 IO 异常突增的场景发挥的作用。
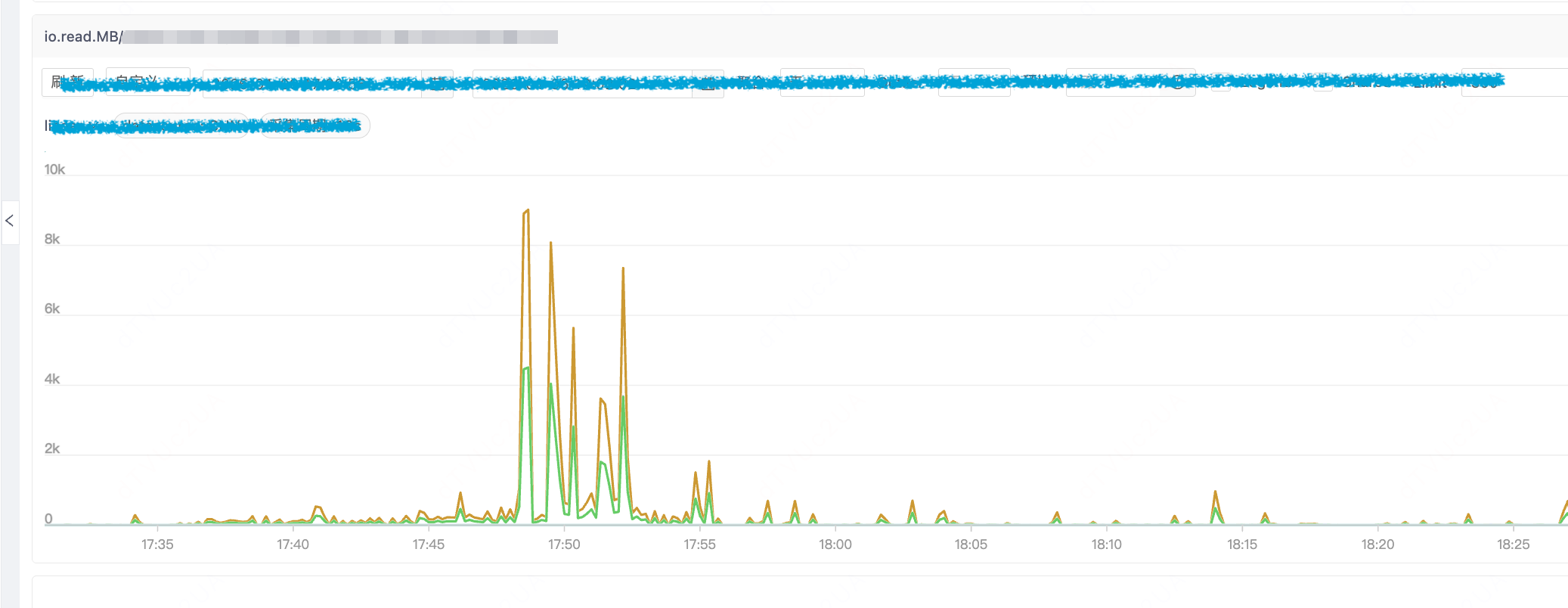
HUATUO 观测到服务器在 17:50 左右发生一次大量读磁盘请求。
技术原理
iotracing 实现原理核心架构如下图:

总结
HUATUO iotracing 将打造 IO 性能分析的终极工具,未来开放更多特性。
篇尾:
- HUATUO(华佗)是由滴滴开源并依托 CCF 孵化的操作系统深度可观测项目。
- 关注微信公众号,或扫码加微信,邀请你加入用户群(请备注姓名+单位):
