
最后更新: 2026-03-15, 作者: HAO022
业务介绍
redis 作为核心存储组件,对实时性要求非常高。如果系统某些地方出现性能干扰,redis 就会出现较大的查询延迟,拖慢整个链路的响应速度。本文我们通过使用 HUATUO 提供的指标,对 redis 的性能瓶颈做了详细的分析,给出解决方案,最终访问 redis 的业务层面的延迟直接降低 30%,效果显著。
问题背景
redis 服务长期运行后会出现性能下降,为了定位该问题则需要查阅一系列指标,而 HUATUO 则提供了非常详细的系统指标,从CPU到内存都可以观测。本次使用的内存指标叫做
huatuo_bamai_vmstat_numa_pages_migrated
huatuo_bamai_vmstat_container_numa_pages_migrated
这两个指标记录了系统上因为 numa balance 而造成的页面迁移次数,后者更是精确到容器层面。当 redis 延迟升高时,这个指标也非常高,两者的趋势是一致的。redis 是内存数据库,几乎所有操作都是内存访问,如果在 page fault 里做额外的页面迁移,那势必会导致访问延迟。
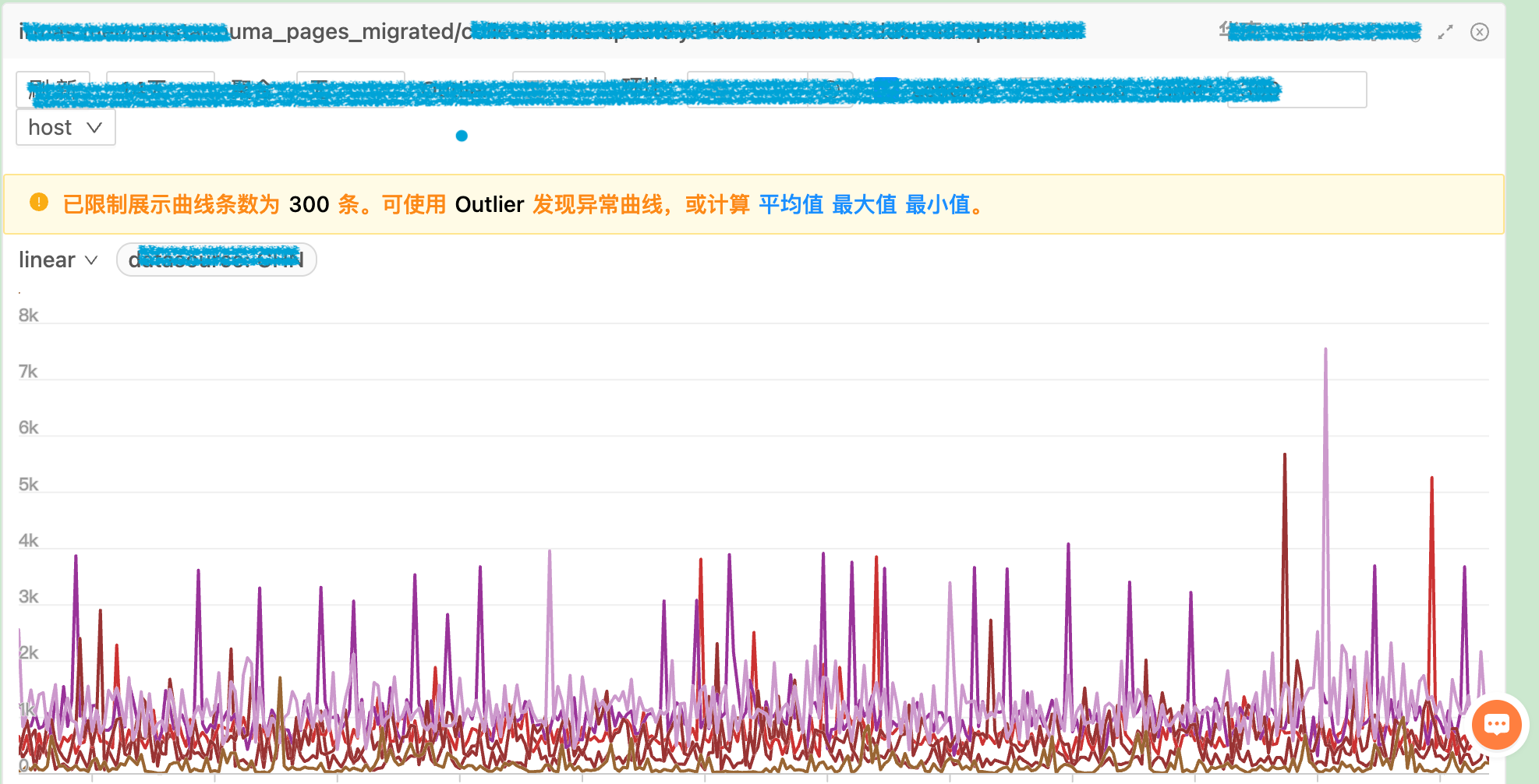
进一步发现,当 redis 进行 aof 操作时 nr_inactive_file 和 nr_active_file 指标均会升高,这直接造成 nr_free_pages 下降。如果一个 redis 进程的 aof 文件过大或者比较频繁,则文件缓存持续的占用内存,最后会导致 redis 进程所在 node 节点的空闲内存减少,后续的内存分配会从另一个空闲的 node 分配,为 numa balance 创造了条件。
综上,通过对 HUATUO 指标的详细分析,可以归纳出触发 numa balance 的两点:
- 随着负载变化 redis 进程会在 node 之间迁移,导致它的内存分散在两个内存节点上。
- redis 不定期的进行数据备份,将数据保存在文件里,这些磁盘数据在写完之后一般就不会使用。尽管数据不再使用,但是它仍然留在文件缓存里,这会导致某个 node 可用内存特别少,后续的内存分配会自动从另一个较空闲的 node 分配。
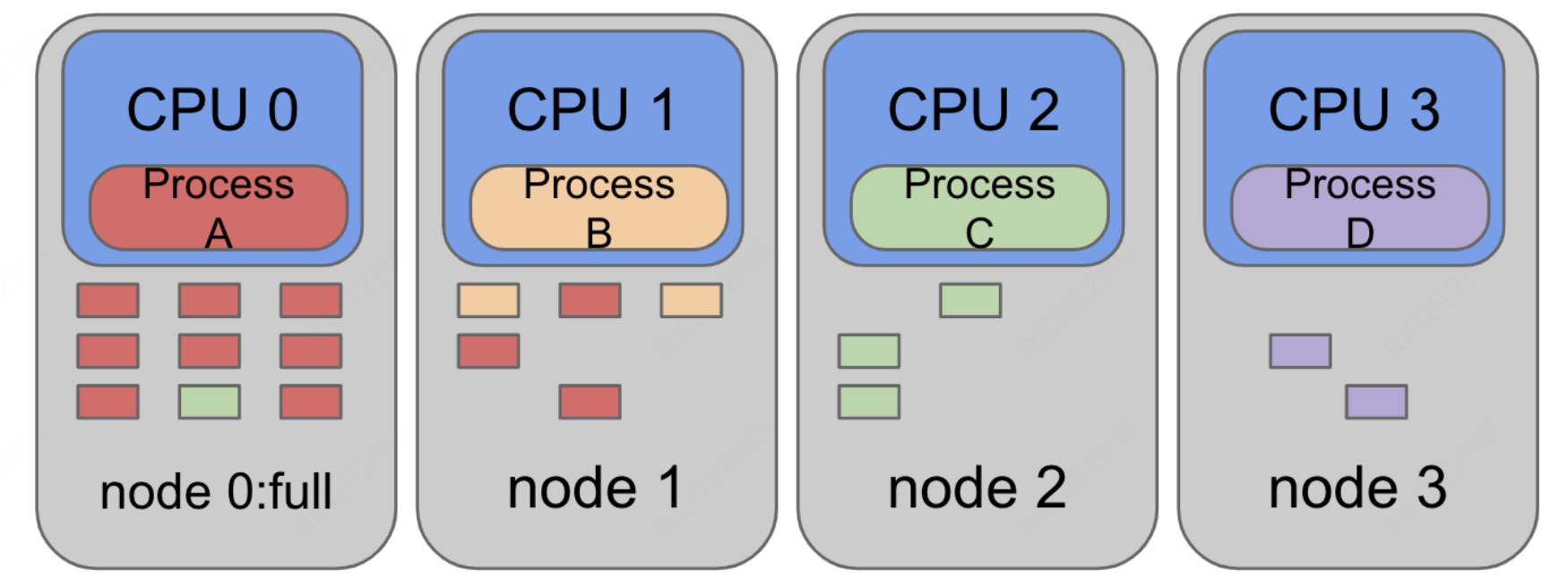
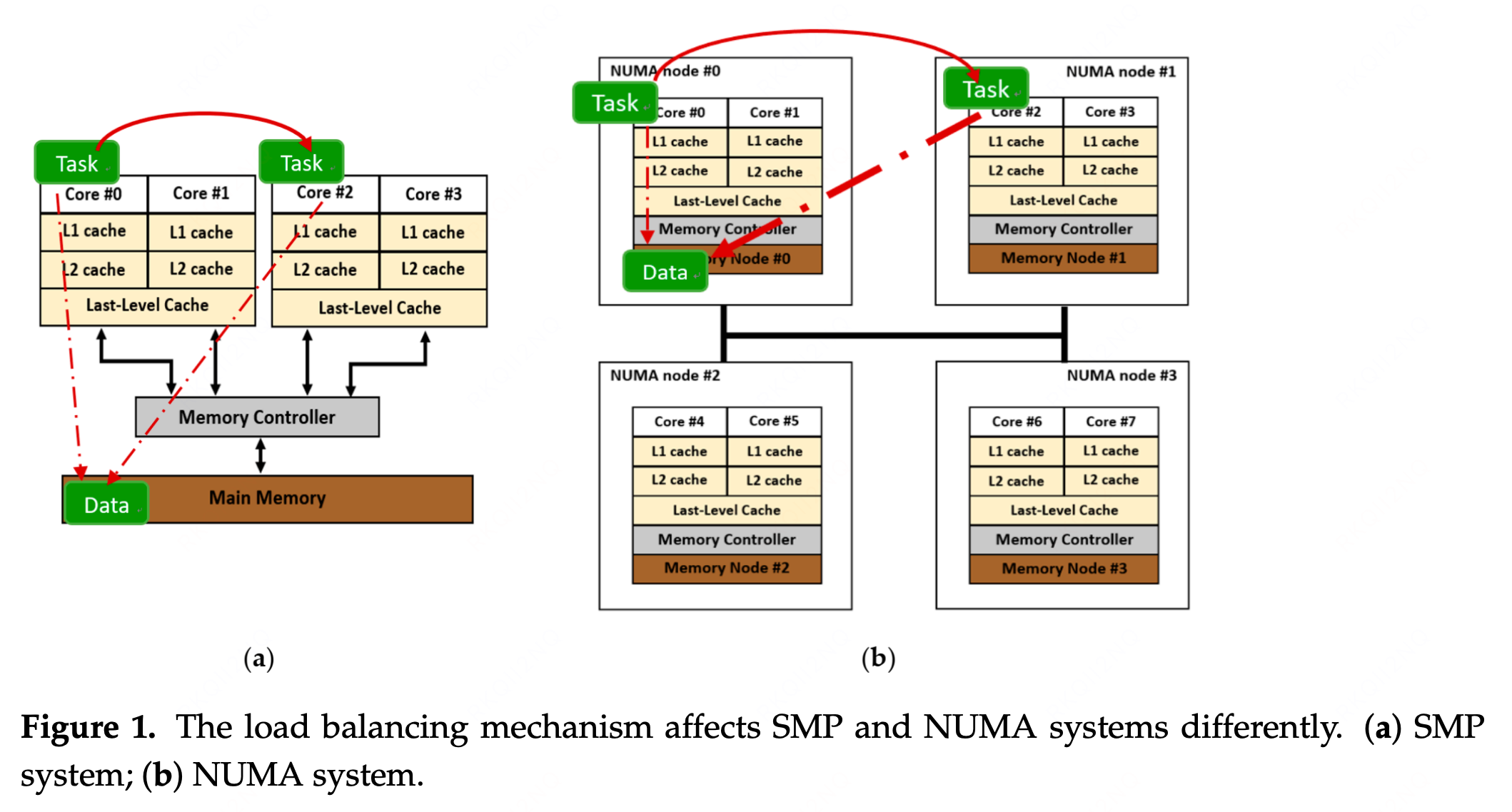
调优方法和原理分析
提升内存水位
针对机器上大量 pagecache 占据空间,鉴于这些 cache 都是 aof 备份文件的缓存,其属于无用内存,可以随时释放。我们就把 vm.watermark_scale_factor 设定为 1000,内核最终的 low 水位被设定为总内存的 1/10,这样 kswapd 可以频繁的回收文件缓存,让 free 内存保持在一个合理的水平,内存的分配就不会被迫横跨节点了。实测表明 numa miss 减少到接近 0,业务性能整体提高。
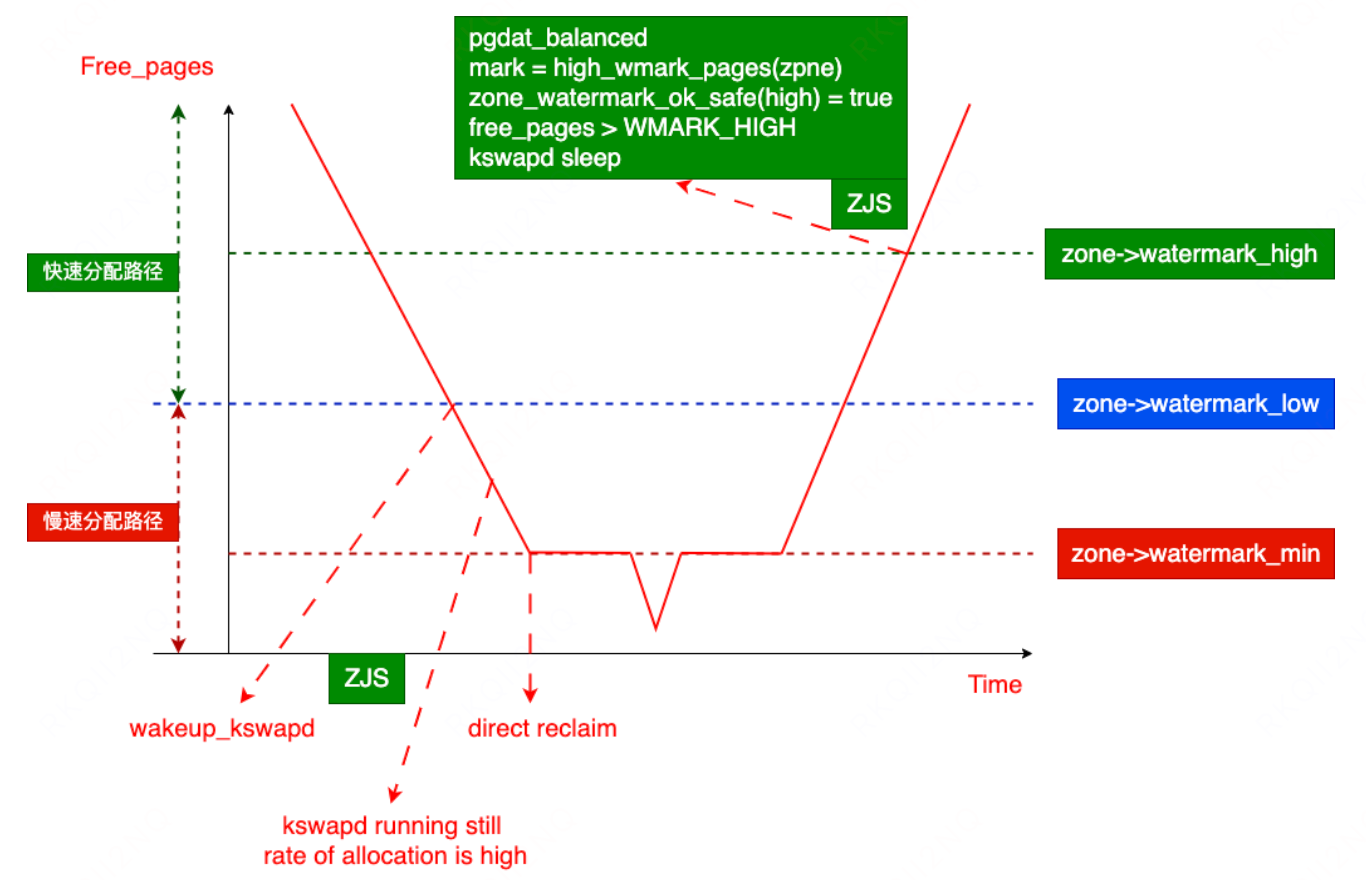
关于 vm.watermark_scale_factor
-
该参数用于控制内存水位的间距,从而影响内核的内存回收行为,主要是 kswapd 守护进程的唤醒和睡眠时机。
-
该参数不改变 min 水位,只影响 min 水位到 low 和 high 的间距。
-
默认值为 10(对应总内存的 0.1%),取值范围为 0-3000(即 0% 到 30%)。
WMARK_LOW = WMARK_MIN + (zone->managed_pages * vm_watermark_scale_factor) / 10000 WMARK_HIGH = WMARK_LOW + (zone->managed_pages * vm_watermark_scale_factor) / 10000 vm.watermark_scale_factor=1000
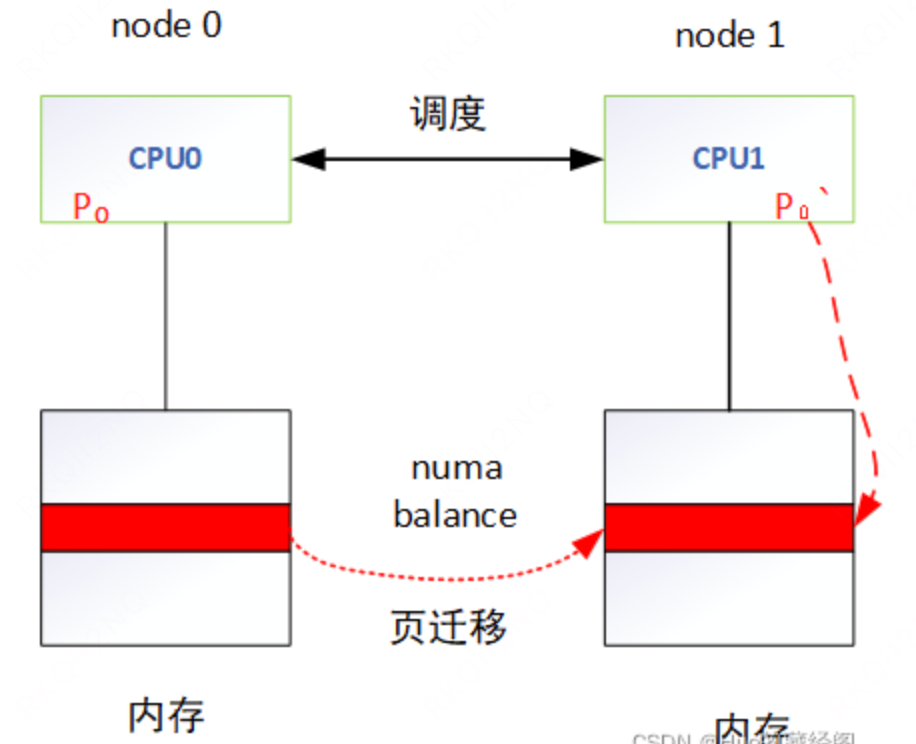
关闭 numa balancing
numa balance 调度策略会在进程尝试访问远端 numa node 内存的时候把远端 numa node 上的内容复制到本地,目的是提高访存速度,但内存搬移本身是有损耗的。在实际工作中,数据库或者内存带宽敏感型的服务需要关闭 numa balance。
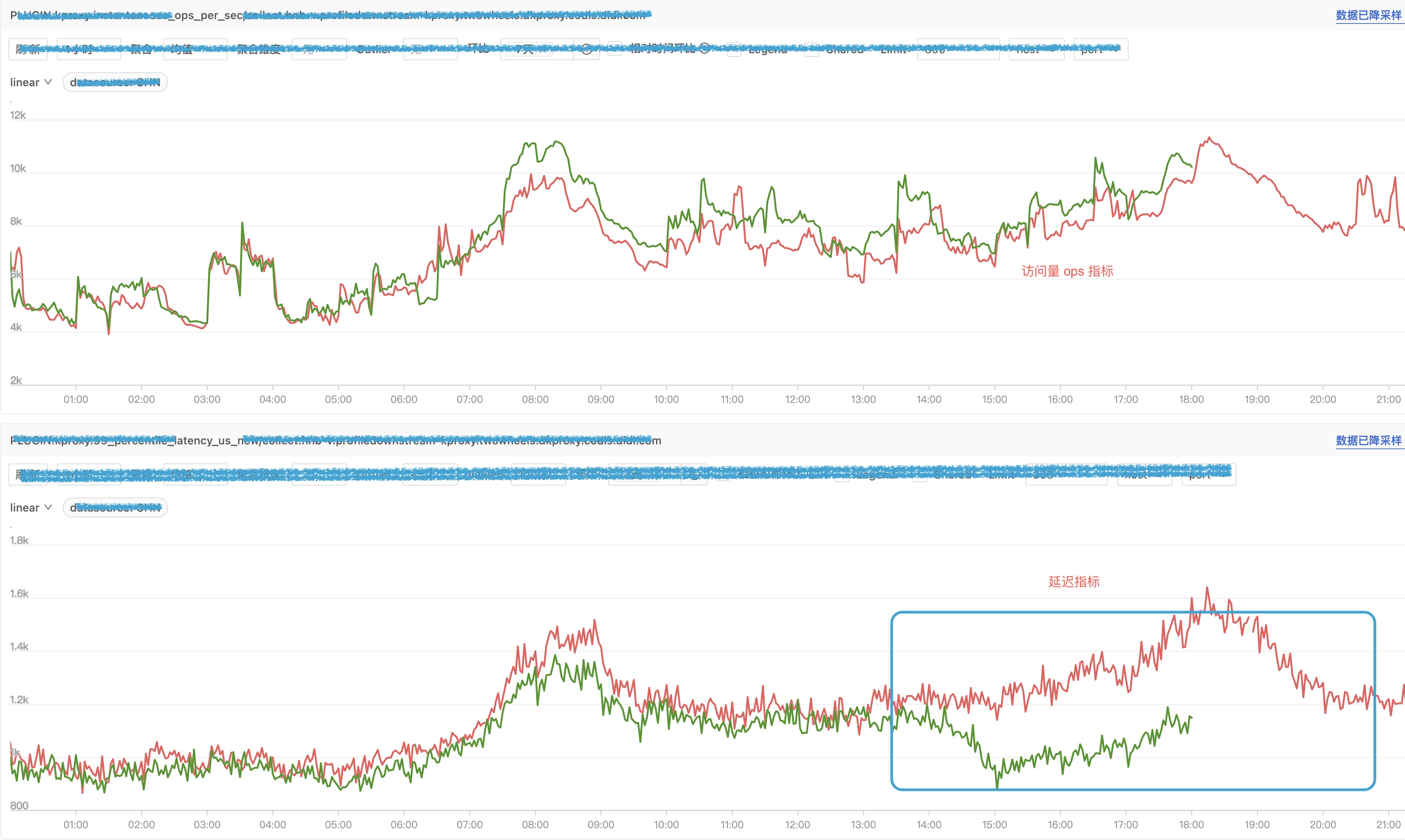
优化效果
调整集群A
调整了业务集群A宿主机参数,得到的效果是周五晚高峰 P99 均值从 9.2ms 降为 5.7ms,下降约37%。

调整集群B
集群内能观察到关闭 numa balance 策略后的 P99 耗时有明显的下降。
总结
本次定位过程由现象开始,随后通过查看 HUATUO 在内存上的详细指标,进而推测出系统所处于的状态,并进而定位到性能的瓶颈所在,最后根据我们对内核的理解给出了解决方案。
篇尾:
- HUATUO(华佗)是由滴滴开源并依托 CCF 孵化的操作系统深度可观测项目。
- 关注微信公众号,或扫码加微信,邀请你加入用户群(请备注姓名+单位):

- 仓库1:https://github.com/ccfos/huatuo
- 仓库2:https://gitlink.org.cn/ccfos/huatuo
- 官网:https://huatuo.tech/