
最后更新: 2026-03-15, 作者: teresa
问题描述
在网络性能监测中,丢包量是关键指标之一。传输层丢包通常由协议栈自行记录,而网卡设备丢包则常因AOC模块不可用、网卡收发队列满载或物理链路错误等原因引发。如何有效监测此类丢包情况,成为一项实际挑战。
问题现状
目前,网络层丢包量通常通过 rx_dropped 指标进行统计,该指标也是网络设备监控的常用依据。然而,rx_dropped 并未进一步区分硬件层面丢包与协议栈统计的丢包,导致根因定位存在困难。
查看指标
针对于上述场景,HUATUO 提供了专门针对硬件层面的丢包量。安装 HUATUO,执行:
curl -X GET http://localhost:19704/metrics | grep -i netdev_hw
获取指标
# HELP huatuo_bamai_netdev_hw_rx_dropped count of packets dropped at hardware level
huatuo_bamai_netdev_hw_rx_dropped{device="eth0",driver="XXX",host="XXXXXX",region="XXX"} 1.230197e+06
实际案例
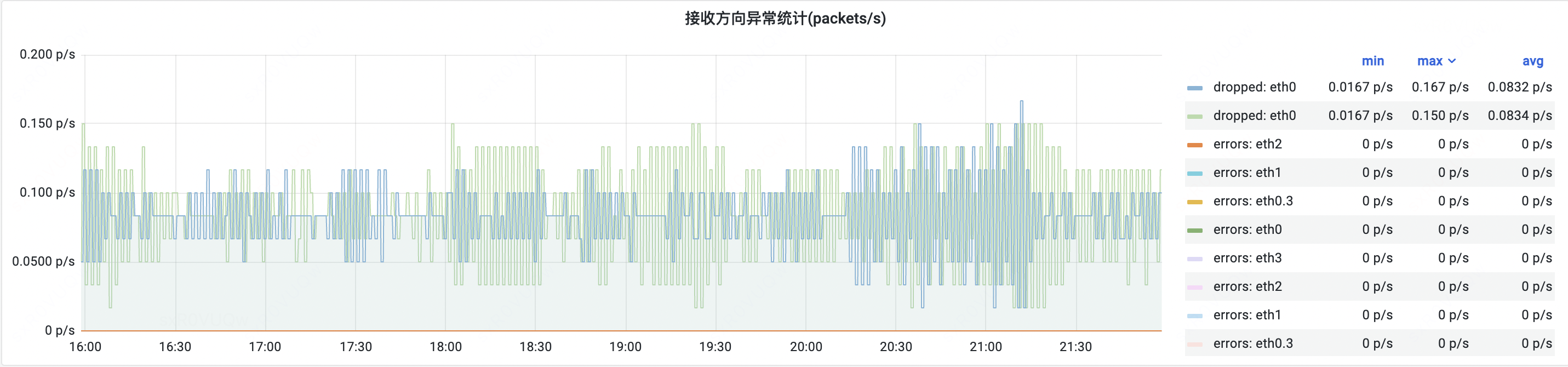
- 问题描述:某上游业务容器报传输层在 16:00 ~ 17:00 时间内 SYN-ACK 丢包,可以看到此业务容器网络流量并无大波动,且出方向并无 dropped。
- 入向:
- 出向:
- 问题定位:HuaTuo 根因定位 dropwatch 工具可检测报文丢失情况,并无相关机器丢包输出,则说明此 SYN-ACK 数据包并不在协议栈。
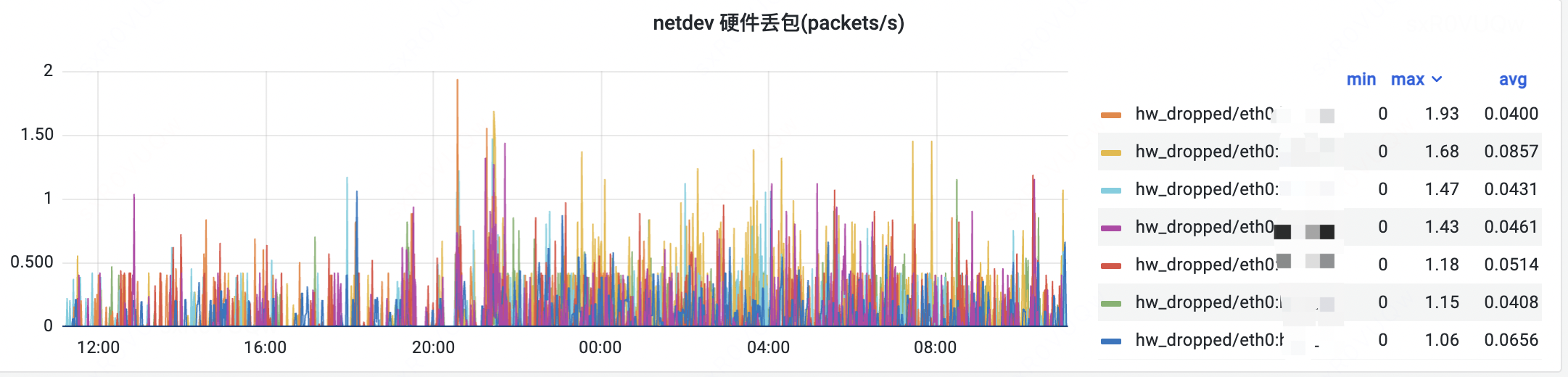
- 此容器所在宿主机器网络流量入向有丢包:
- 根据 ethtool 可以看到其 dropped 累积量较大。同时观测到 huatuo 硬件丢包在持续增加。
网卡硬件丢包设计
1. 有哪些困难?
在实现硬件丢包指标的过程中,引入了几类困难:
- 厂商网卡驱动实现不统一,同样的统计项在不同驱动里可能含义不同或根本不提供;
- ethtool 工具不适合长时间在可观测场景中使用;
因此我们需要一个兼容多驱动、低侵入、避免锁竞争且具有可验证性的 通用监控方案。
2. 为什么不能依赖 ethtool?
ethtool 的用户空间工具通过 ioctl(SIOCETHTOOL) 进入内核,内核在处理此类请求时会在 dev_ioctl 分支里拿 rtnl 大锁:
int send_ioctl(struct cmd_context *ctx, void *cmd)
{
ctx->ifr.ifr_data = cmd;
return ioctl(ctx->fd, SIOCETHTOOL, &ctx->ifr);
}
/* 内核中 dev_ioctl 处理 SIOCETHTOOL 时会加上 rtnl 锁 */
case SIOCETHTOOL:
dev_load(net, ifr->ifr_name);
rtnl_lock(); // -> 这里会全局串行化 dev_ethtool 的调用
ret = dev_ethtool(net, ifr);
rtnl_unlock();
这意味着所有通过 ethtool 的操作都可能在内核中串行执行(持锁期间),在大量网口或高并发查询场景,会引起显著的延迟和锁竞争风险,因此不应作为高频次实时监控的主路径。
3. 内核中的丢包统计
内核通过 dev_get_stats 给上层(例如 /proc/net/dev、sysfs)提供一份 rtnl_link_stats64 统计结构:
struct rtnl_link_stats64 *dev_get_stats(struct net_device *dev,
struct rtnl_link_stats64 *storage)
{
const struct net_device_ops *ops = dev->netdev_ops;
if (ops->ndo_get_stats64) {
memset(storage, 0, sizeof(*storage));
ops->ndo_get_stats64(dev, storage); // 驱动层面统计(通常为“硬件丢包”)
}
/* 软件丢包统计累加 */
storage->rx_dropped += (unsigned long)atomic_long_read(&dev->rx_dropped);
storage->tx_dropped += (unsigned long)atomic_long_read(&dev->tx_dropped);
storage->rx_nohandler += (unsigned long)atomic_long_read(&dev->rx_nohandler);
return storage;
}
-
ops->ndo_get_stats64:由驱动实现,通常反映驱动/硬件层面的统计(被我们称为 硬件丢包)。
-
dev->rx_dropped:协议栈在运行时维护并更新的计数(我们称为 软件丢包)。
-
内核对这些计数的注释中还说明,rx_dropped 表示被接收但未处理的包,而像 rx_missed_errors 这类字段通常用于设备层未捕获/被丢弃的包。 /proc/net/dev 会把两者合并显示为“drop”列。
4. 不同驱动实现差异
实践中我们发现:不同厂商的网卡驱动对“硬件丢包/总丢包”的实现方式并不统一:
- ixgbe、bnxt:会单独维护并暴露 rx_missed_errors(硬件丢包),可以直接读取 sysfs 的 rx_missed_errors 作为硬件丢包指标;
- mlx5、i40e:没有单独输出硬件丢包字段,或者驱动内部把某些计数混合到了 rx_dropped,这时需要额外手段将“软件丢包”剥离出来,才能估算出真实的硬件丢包;
因此我们的实现流程为:
5. BPF 实现示例
/* BPF map:key 是 ifindex,value 是累积的软件丢包数 */
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__type(key, u32);
__type(value, u64);
__uint(max_entries, 1024);
} rx_sw_dropped_stats SEC(".maps");
/* 示例 kprobe:位置根据目标内核/需求选择(这里仅作示意);
可针对触发软件丢包的函数点放置 kprobe(例如协议栈返回丢弃路径处)。*/
SEC("kprobe/example_drop_path")
int BPF_KPROBE(record_sw_drop, struct device *dev)
{
struct net_device *netdev = container_of(dev, struct net_device, dev);
u32 ifindex = BPF_CORE_READ(netdev, ifindex);
/* 注意:不同内核对 rx_dropped 的存储类型不同,可能需要 BPF_CORE_READ(..., rx_dropped.counter)
或者直接 BPF_CORE_READ(..., rx_dropped)。具体以编译时 CO-RE 抛出的结果为准。 */
u64 sw = 0;
sw = BPF_CORE_READ(netdev, rx_dropped);
bpf_map_update_elem(&rx_sw_dropped_stats, &ifindex, &sw, BPF_ANY);
return 0;
}
篇尾:
- 关注微信公众号【HUATUO 开源技术】留言,或扫码添加工作人员微信,邀请您加入用户群(请备注姓名+单位):

- 代码仓库:https://github.com/ccfos/huatuo
- 官方网站:https://huatuo.tech/