最后更新: 2026-02-13, 作者: fanzu8
背景与问题
在网络性能监控和优化中,入向延迟是一个关键指标。生产环境中通常面临如下问题:
-
- 本地 app 没收到包,对端却已超时
-
- 本地 app 收到包却延迟,但不确定延迟在哪个阶段(对端发出、链路延迟还是本侧网卡、调度、软中断、协议栈、app 性能瓶颈等)
本文讨论问题 2 中,从本机网卡到 app 主动收取包过程中,可能存在的延迟点。
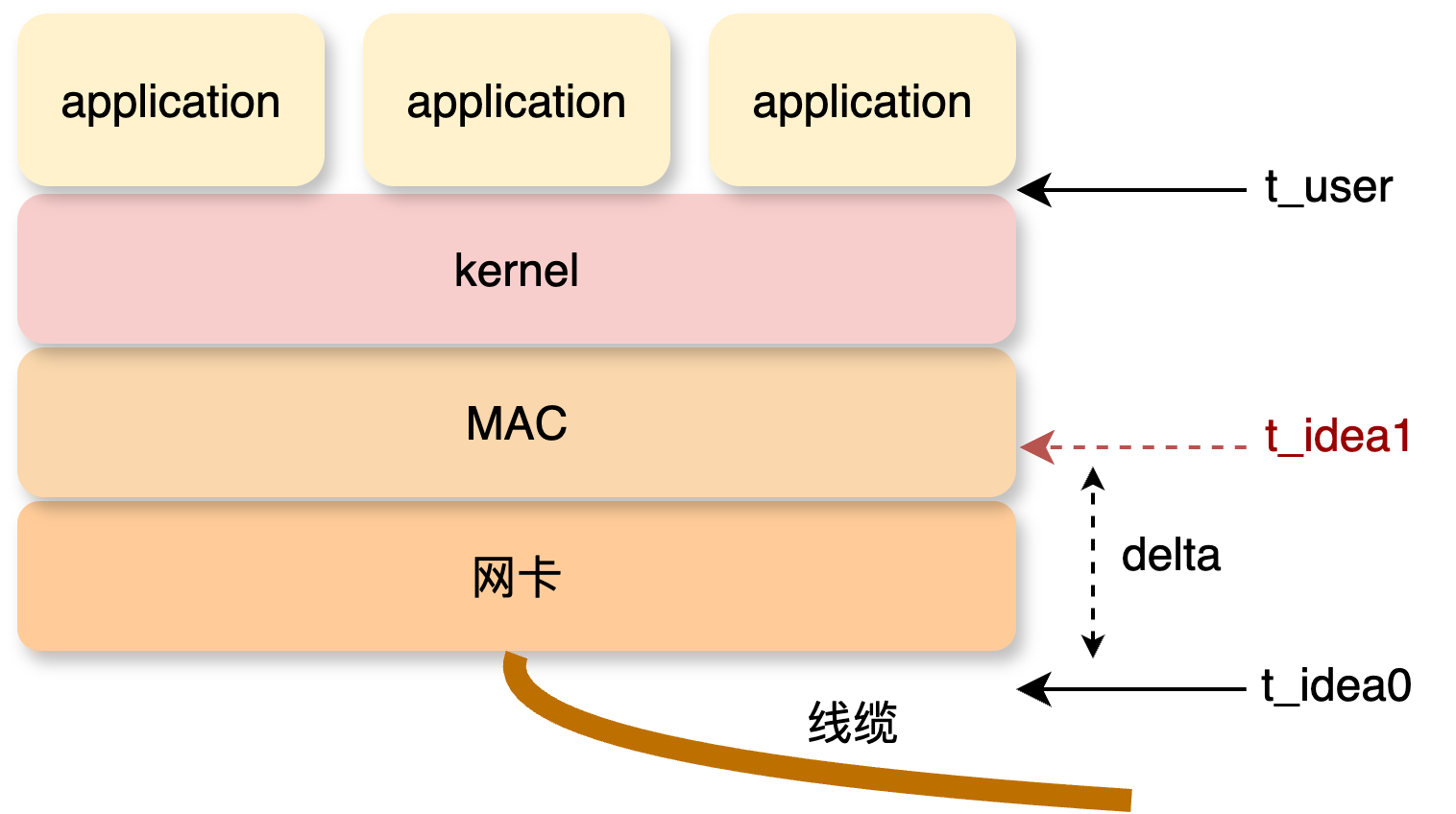
理想状态我们希望从网线末端就拿到报文的时间戳 t_ideal0 作为报文到达本机的时间点,用户态主动取走报文的时间作为 t_user,这样 t_user - t_ideal0 就是本机收取报文的完整耗时。显然对于 t_ideal0 的获取是不可能的,那么至少要在网卡固件或者驱动甚至更上层获取个 t_ideal1 应该不过分,delta = t_ideal1 - t_ideal0,因此本机收到报文的初始时间获取问题转换为如何使 delta 尽可能小,也就是说在尽量靠近网卡的位置找一个能打时间戳的点。
看下网卡侧的打时间戳的 Capabilities:
$ ethtool -T eth0 # -T Show time stamping capabilities
Time stamping parameters for eth0:
Capabilities:
hardware-transmit (SOF_TIMESTAMPING_TX_HARDWARE)
hardware-receive (SOF_TIMESTAMPING_RX_HARDWARE)
hardware-raw-clock (SOF_TIMESTAMPING_RAW_HARDWARE)
PTP Hardware Clock: 0
Hardware Transmit Timestamp Modes:
off (HWTSTAMP_TX_OFF)
on (HWTSTAMP_TX_ON)
Hardware Receive Filter Modes:
none (HWTSTAMP_FILTER_NONE)
all (HWTSTAMP_FILTER_ALL)
内核提供通过系统调用 setsockopt 开启报文自动打上时间戳的选项 SO_TIMESTAMPING:
err = setsockopt(fd, SOL_SOCKET, SO_TIMESTAMPING, &val, sizeof(val));
再看下用户侧如何从报文中获取时间戳, 内核通过 cmsg 把报文的时间戳信息返回上层:
/**
* struct scm_timestamping - timestamps exposed through cmsg
*
* The timestamping interfaces SO_TIMESTAMPING, MSG_TSTAMP_*
* communicate network timestamps by passing this struct in a cmsg with
* recvmsg(). See Documentation/networking/timestamping.txt for details.
*/
struct scm_timestamping {
struct timespec ts[3];
};
其中还包括了底层硬件记录的时间戳:
static void tcp_update_recv_tstamps(struct sk_buff *skb,
struct scm_timestamping *tss)
{
if (skb->tstamp)
tss->ts[0] = ktime_to_timespec(skb->tstamp);
else
tss->ts[0] = (struct timespec) {0};
if (skb_hwtstamps(skb)->hwtstamp)
tss->ts[2] = ktime_to_timespec(skb_hwtstamps(skb)->hwtstamp);
else
tss->ts[2] = (struct timespec) {0};
}
我们能不能利用这个时间戳将网络报文收方向的延迟做到分阶段计算并通用化呢?继续往下分析。
时间戳存放位置
时间戳在 skb 中的存放位置有两个地方:
-
skb->tstamp 在
sk_buff的union里:struct sk_buff { ... union { ktime_t tstamp; u64 skb_mstamp; }; ... } -
底层硬件时间戳存放在
sk_buff的skb_shared_info结构中,通过skb_hwstamps(skb)->hwstamp得到其指针,然后读取或修改。#define skb_shinfo(SKB) ((struct skb_shared_info *)(skb_end_pointer(SKB))) ... static inline struct skb_shared_hwtstamps *skb_hwtstamps(struct sk_buff *skb) { return &skb_shinfo(skb)->hwtstamps; } ... struct skb_shared_hwtstamps { ktime_t hwtstamp; };
硬件时间戳
硬件时间戳由网卡驱动实现的 napi 的 poll 接口提供,这里给出 mlx 和 ixgbe 的部分驱动代码调用关系作参考:
mlx5: netif_napi_add(netdev, &c->napi, mlx5e_napi_poll, 64);
mlx5e_napi_poll
mlx5e_poll_rx_cq
mlx5e_handle_rx_cqe
mlx5e_complete_rx_cqe
mlx5e_build_rx_skb
skb_hwtstamps(skb)->hwtstamp =mlx5_timecounter_cyc2time(rq->clock, get_cqe_ts(cqe));
ixgbe: netif_napi_add(adapter->netdev, &q_vector->napi, ixgbe_poll, 64);
ixgbe_poll
ixgbe_clean_rx_irq
ixgbe_process_skb_fields
ixgbe_ptp_rx_hwtstamp
ixgbe_ptp_rx_rgtstamp
ixgbe_ptp_convert_to_hwtstamp(adapter, skb_hwtstamps(skb), regval);
skb_hwtstamps(skb)
可以看到 mlx 和 ixgbe 打硬件时间戳的方式有所不同,其中 ixgbe 还依赖 PTP(Precision Time Protocol) 方式去生成硬件时间戳。
验证看看开启硬件时间戳后收到的数据长什么样,开启网卡收包时间戳:
$ hwstamp_ctl -r 1 -i eth0 # -r [0..14] select receive time stamping: 1 time stamp any incoming packet
current settings:
tx_type 0
rx_filter 0
new settings:
tx_type 0
rx_filter 1
硬件时间戳存放在 sk_buff 的 skb_shared_info 结构中,通过 skb_hwstamps(skb)->hwstamp 获取其指针, bpftrace 工具中将函数层层展开如下,
在点 netif_receive_skb 用 bpftrace 工具验证:
$ bpftrace -e 'tracepoint:net:netif_receive_skb {$skb = (struct sk_buff *)args->skbaddr; printf("%llx\n", ((struct skb_shared_info *)($skb->head + $skb->end))->hwtstamps.hwtstamp);}'
// 开启前
0
0
...
0
// 开启后
1698221031030014635
0
...
1698221056659251659
需要注意的是在驱动层打时间戳的方法 timecounter_cyc2time() 或者 ixgbe_ptp_convert_to_hwtstamp 与上层获取到的内核提供的墙上时钟时间戳的 ktime_get_real() 存在偏差,本地测试发现其偏差随时间推移逐渐变化,不是简单的线性关系,涉及 ptp 主从时间同步,在用 linuxptp 同步之后明显偏差减小但依然存在,这与驱动从网卡 phc 获取时间的具体实现有关,需要搞清 phc、ptp 这一块不同驱动的实现才能更好的利用硬件时间戳,当然也可以定期读取 phc 的时间戳与系统时间戳计算 offset 作为参考值。phc 时间戳获取可通过 SYS_CLOCK_GETTIME 实现,offset 的估计值计算方法参考: https://github.com/facebook/time/blob/main/phc/offset.go#L83,
因此想通过在最靠近网线的网卡层获取报文到达本机的初始时间没那么简单。
软件时间戳
再往上一层找,好像除了内核协议栈收包入口函数 netif_receive_skb 再没有一个距离网卡更近一点的一个统一入口了。对代码进行梳理然后逐个分析是否存在 netif_receive_skb 调用前还有打时间戳的地方:
非 NAPI:
netif_rx
netif_rx_internal
enqueue_to_backlog
softnet_data.input_pkt_queue -> backlog -> softnet_data.poll_list
软中断
net_rx_action
process_backlog
__netif_receive_skb
NAPI:
IRQ
napi_schedule
softnet_data.poll_list
软中断
poll
napi_gro_receive
netif_receive_skb_internal
__netif_receive_skb
发现无论是走 napi 还是不走 napi 的路径都有在上送协议栈前打时间戳的地方,看来是有希望:
-
不走 napi
... netif_rx_internal net_timestamp_check(netdev_tstamp_prequeue, skb); <-- enqueue_to_backlog ... -
走 napi
... netif_receive_skb_internal net_timestamp_check(netdev_tstamp_prequeue, skb); <-- ...
其中 net_timestamp_check 相关实现如下:
#define net_timestamp_check(COND, SKB) \
if (static_branch_unlikely(&netstamp_needed_key)) { \
if ((COND) && !(SKB)->tstamp) \
__net_timestamp(SKB); \
} \
static inline void __net_timestamp(struct sk_buff *skb)
{
skb->tstamp = ktime_get_real(); <-- 内核打印的时间戳(wall time)
}
$ sysctl -a |grep netdev_tstamp_prequeue
net.core.netdev_tstamp_prequeue = 1 <-- 决定打时间戳位置在 RPS 前
# 如何开启打此时间戳的功能可参考 HUATUO 代码
但是这样,从上面调用路径的解析可以清楚看到对于走 NAPI 的路径的报文就没办法覆盖软中断的延迟了,也就是说这个 delta 稍微大了一点点,不过也还行,也还能用,这样报文到达本机的初始时间戳 ts0 就差不多解决了。
计算延迟
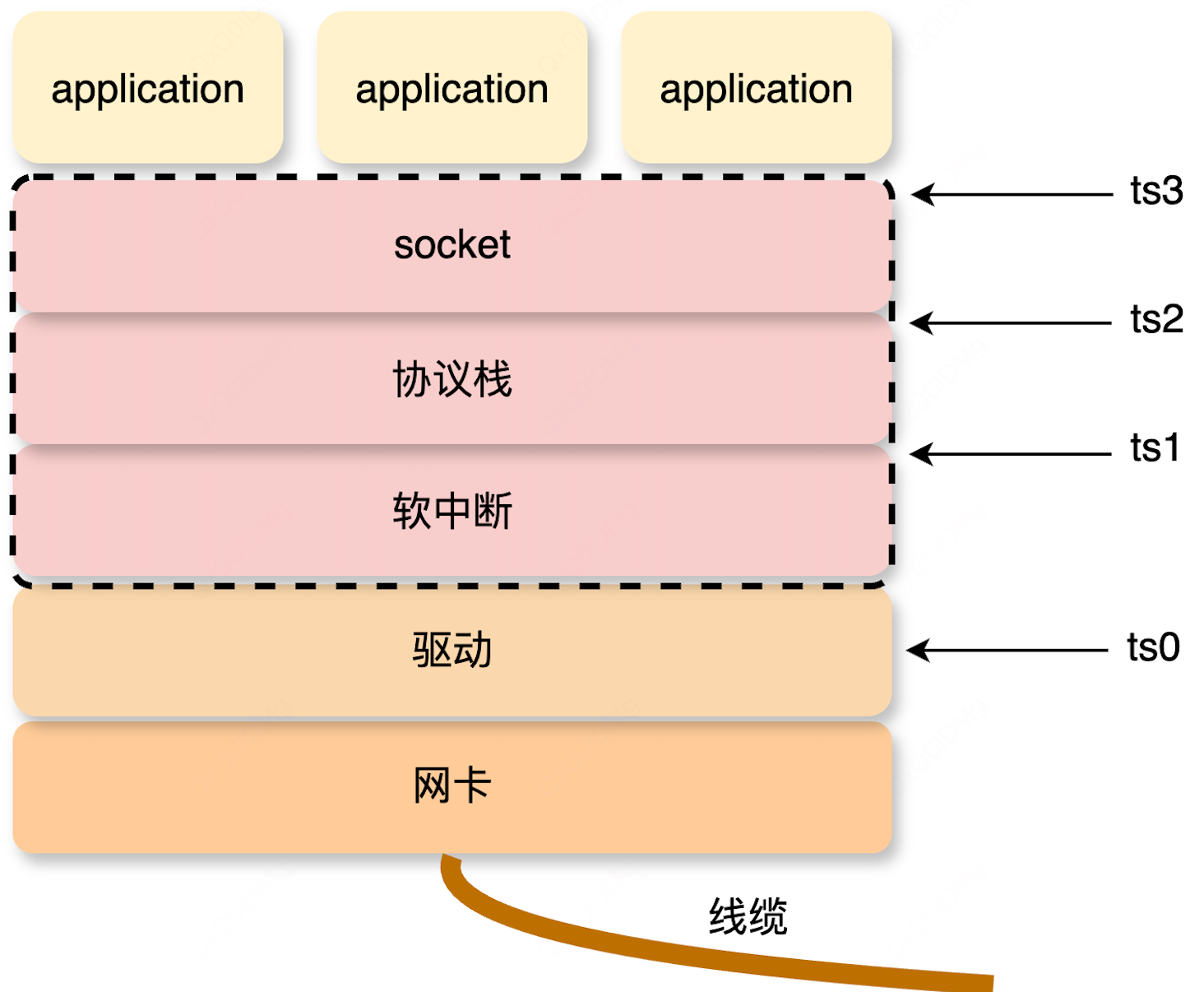
-
协议栈入口
前面有提到
netif_receive_skb为协议栈统一入口函数,内核也有 tracepoint 点,在这里获取时间戳ts1作为近似计算驱动、软中断的延迟。 -
协议栈出口
进入协议栈后,报文到达
tcp_v4_rcv可认为协议层处理完毕,因此在tcp_v4_rcv处获取时间戳ts2作为计算协议栈的延迟的基础。 -
用户主动取包
接下来是用户进程主动调用到
tcp_recvmsg从 skb 将数据拷贝到 socket 缓冲区, 综合性能损耗和是否通用且是否易于实现,这里选取skb_copy_datagram_iovec点作为用户收包的时间点ts3。/** * skb_copy_datagram_iter - Copy a datagram to an iovec iterator. * @skb: buffer to copy * @offset: offset in the buffer to start copying from * @to: iovec iterator to copy to * @len: amount of data to copy from buffer to iovec */ int skb_copy_datagram_iter(const struct sk_buff *skb, int offset, struct iov_iter *to, int len) { trace_skb_copy_datagram_iovec(skb, len); return __skb_datagram_iter(skb, offset, to, len, false, simple_copy_to_iter, NULL); }
小结一下:
- 近似计算驱动、软中断的延迟:
ts1 - ts0 - 协议栈延迟:
ts2 - ts1 - 用户主动取包延迟:
ts3 - ts2
由前面可知,ts0 是内核函数 ktime_get_real 生成的软件的时间戳,
/**
* ktime_get_real - get the real (wall-) time in ktime_t format
*/
static inline ktime_t ktime_get_real(void)
{
return ktime_get_with_offset(TK_OFFS_REAL);
}
其格式为 SKB_CLOCK_REALTIME 墙上时钟。为了做到无侵入更通用化,ts1/2/3 的获取可由 bpf 实现,在 kernel v6.1 前 bpf helper 里只提供了 bpf_ktime_get_ns 其格式为 SKB_CLOCK_MONOTONIC,两种时间戳格式的偏移估算以及上述三个阶段的延迟计算方法详情可参考 HUATUO 代码。
总结:
以上就是 HUATUO 网络收包延迟 netrecvlat 方案的核心逻辑,可以看到此收方向延迟事件方案并没有把检测粒度细化到网卡驱动、vlan 转发、RPS 等环节的耗时,除了考虑到性能消耗和实现存在一定的难度外,还考虑到目前方案在解决通用问题也完全够用。
应用
-
软中断优化
loopback 接口会在
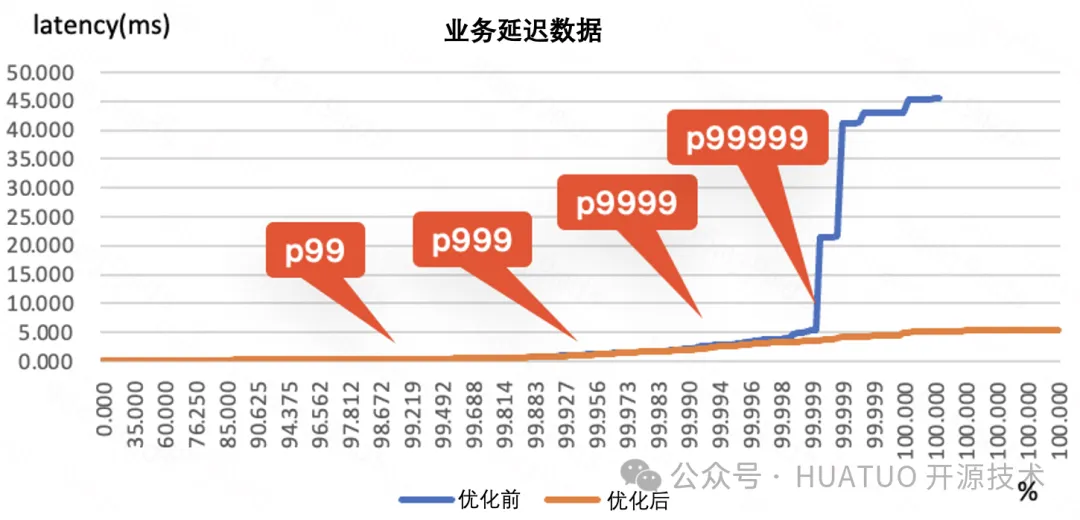
loopback_xmit中将时间戳清零,netrecvlat 能计算使用 loopback 接口(走非 napi 路径)通信的报文在软中断中的延迟,因此可通过对 loopback 发压得到包含软中断延迟(ts1 - ts0) 的数据,然后参考该数据对软中断做相关优化,但需要注意的是软中断是针对系统全局的机制,通常优化软中断在业务指标上没有直接的效果,不会带来能立刻看到的明显业务收益,更多的是表现在业务指标的长尾优化。软中断优化前后 netrecvlat 事件数量对比

业务长尾优化效果
-
问题定界
在生产环境中,明确 “问题边界” 通常面临两大挑战,我对 “问题边界” 有以下两个维度的理解:
- 定位方向:直接影响根因定位的时效与止损策略的制定,明确的定位方向能够显著提升故障排查效率(抓手🤩)
- 责任划分:确定问题出现的具体环节与对应责任人(分锅🤩)
用户主动从内核取包的时间点
ts3可以将延迟问题划分到用户侧还是内核侧;如果能把硬件时间戳拿到,ts1,ts2能将延迟锁定到是在驱动、软中断还是协议栈。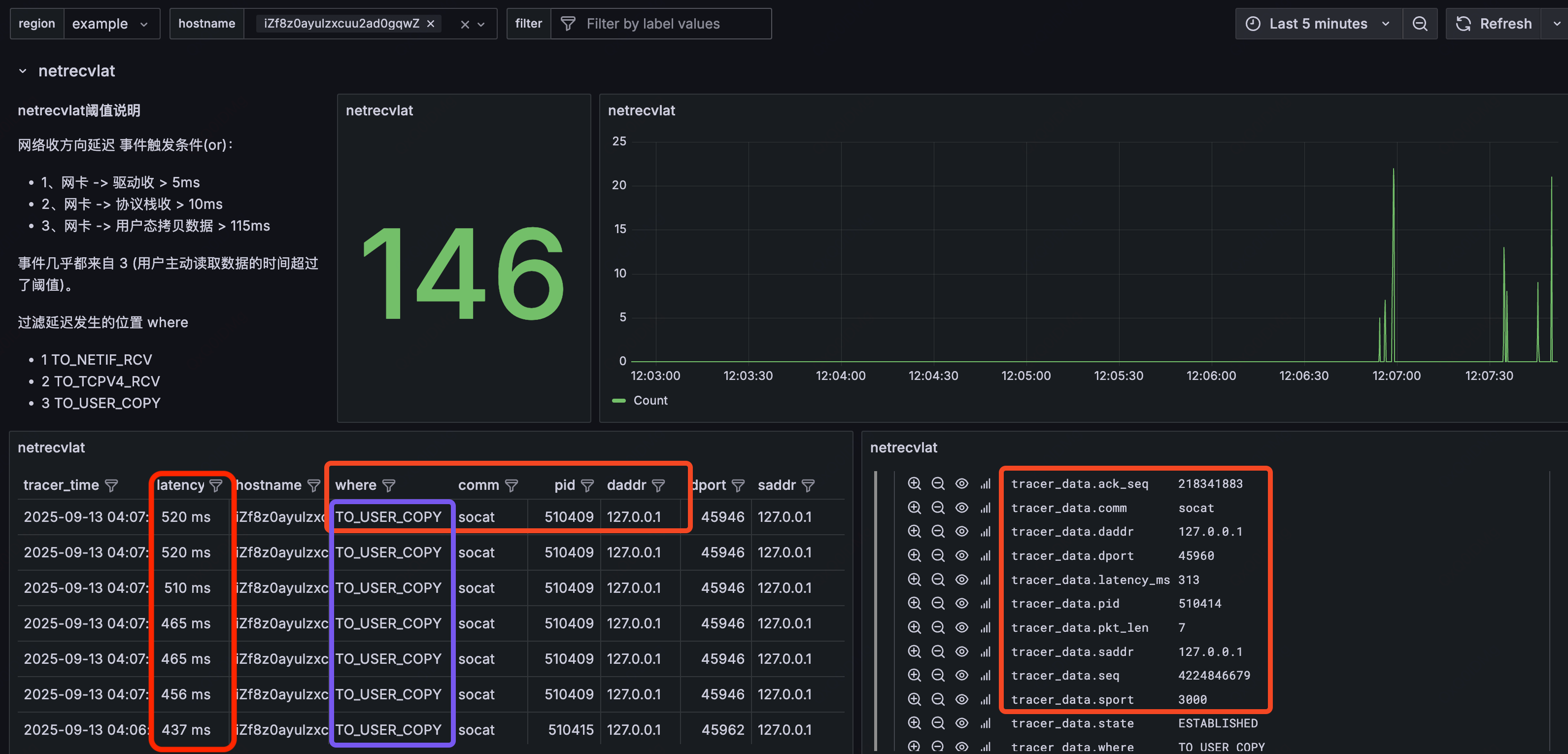
可能存在的问题以及优化点
ts0考虑更稳定准确的硬件时间戳,同时也可以增加走 NAPI 路径的报文包含软中断的延迟检测- 当前使用墙上时钟,跳变/回拨如何处理?
- 高版本内核对 skb 时间戳的处理引入了 tstamp_type 是否可根据不同应用场景设置不同类型的时间值
- 报文分批拷贝到用户接收缓冲区的延迟事件可能存在重复(考虑五元组 或 skb 地址去重?)
- ipv6 支持
- 阈值设置粒度更细(考虑 qos、延迟敏感业务等)
- kernel v5.18 引入 bpf_skb_set_tstamp(),是否会导致阈值失效,如何区分?
参考
- https://github.com/torvalds/linux/blob/v5.10/Documentation/networking/timestamping.rst
- https://github.com/facebook/time
- https://docs.ebpf.io/linux/helper-function/bpf_skb_set_tstamp/
- https://bootlin.com/pub/conferences/2020/elce/tenart-timestamping-and-ptp-in-linux/tenart-timestamping-and-ptp-in-linux.pdf