
最后更新: 2026-04-01, 作者: hao022
概述
系统故障诊断面临多重挑战。首要难点在于故障现场难以保留:生产环境发生故障时,通常操作流程(如容器漂移、流量切换或服务降级)往往会破坏故障现场。即便事后尝试线下复现,也比较有挑战性:一方面,基础架构高度复杂 – K8S 云原生平台引入了容器虚拟化层,而业务混部、资源优先级设定、共享内核以及 Sidecar 等架构特性进一步加剧了复现与诊断的复杂度;另一方面,业务应用间错综复杂的上下游依赖关系也使得完整复现几乎难以实现。更为重要的是,当前行业普遍缺乏高效的操作系统级故障诊断体系:现有开源项目多局限于工具集合或通用指标展示,功能较为零散。因此,如何在新技术范式与架构下,构建面向操作系统的低损耗、零侵扰、全景式、持续深度观测能力体系,成为亟待解决的核心问题。
下面一步步介绍:如何使用 HUATUO 定位容器 CPUIdle 掉底问题
K8S 环境准备
这里简单描述如何快速的构建一个 K8S 环境,具体构建详细步骤参考 K8S 官网。
-
执行如下脚本安装 K8S。
apt install kubelet kubeadm kubectl # kubeadm config images list images=( kube-apiserver:v1.31.10 kube-controller-manager:v1.31.10 kube-scheduler:v1.31.10 kube-proxy:v1.31.10 coredns:v1.11.3 pause:3.10 etcd:3.5.15-0 ) for imageName in ${images[@]}; do docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/${imageName} docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/${imageName} k8s.gcr.io/${imageName} docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/${imageName} done kubeadm reset --force kubeadm init --pod-network-cidr=6.6.0.0/16 \ --apiserver-advertise-address=192.168.122.1 \ --cri-socket=/var/run/containerd/containerd.sock \ --image-repository=registry.aliyuncs.com/google_containers \ --kubernetes-version=v1.31.10 --v=5 kubectl taint nodes --all node-role.kubernetes.io/control-plane- -
创建测试 POD,deployment-fedora42.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: fedora42 spec: replicas: 4 selector: matchLabels: app: fedora42 template: metadata: labels: app: fedora42 spec: containers: - name: fedora42 image: docker.m.daocloud.io/fedora:42 command: ["sleep", "infinity"] imagePullPolicy: IfNotPresent securityContext: privileged: true resources: limits: cpu: 2 memory: 200M requests: cpu: 2 memory: 200M$ kubectl apply -f deployment-fedora42.yaml deployment.apps/fedora42 created $ kubectl get pod NAME READY STATUS RESTARTS AGE fedora42-795b765c6c-fsk84 1/1 Running 0 2m25s fedora42-795b765c6c-jzkqw 1/1 Running 0 2m25s fedora42-795b765c6c-ndwg9 1/1 Running 0 2m25s fedora42-795b765c6c-wkblg 1/1 Running 0 2m25s
HUATUO 环境准备
假设你已经有 kubelet 管理的容器环境,接下来介绍 HUATUO 组件如何启动。
-
下载源代码或者镜像。
$ git clone https://github.com/ccfos/huatuo.git $ cd huatuo $ vim huatuo-bamai.conf -
修改配置文件开启容器问题检测功能,你可以根据实际环境修改配置。
[Pod] KubeletPodClientCertPath = "/etc/kubernetes/pki/apiserver-kubelet-client.crt,/etc/kubernetes/pki/apiserver-kubelet-client.key" -
启动 HUATUO 组件服务。
# 启动组件 $ docker compose --project-directory ./build/docker up [+] Running 4/4 ✔ Container prometheus Running ✔ Container elasticsearch Running ✔ Container grafana Running ✔ Container huatuo-bamai Recreated Attaching to elasticsearch, grafana, huatuo-bamai, prometheus也可根据源码本地构建 HUATUO 镜像,再启动如上 HUATUO 组件服务:
# 本地构建镜像(可选) $ docker build --network host -t huatuo/huatuo-bamai:latest . -
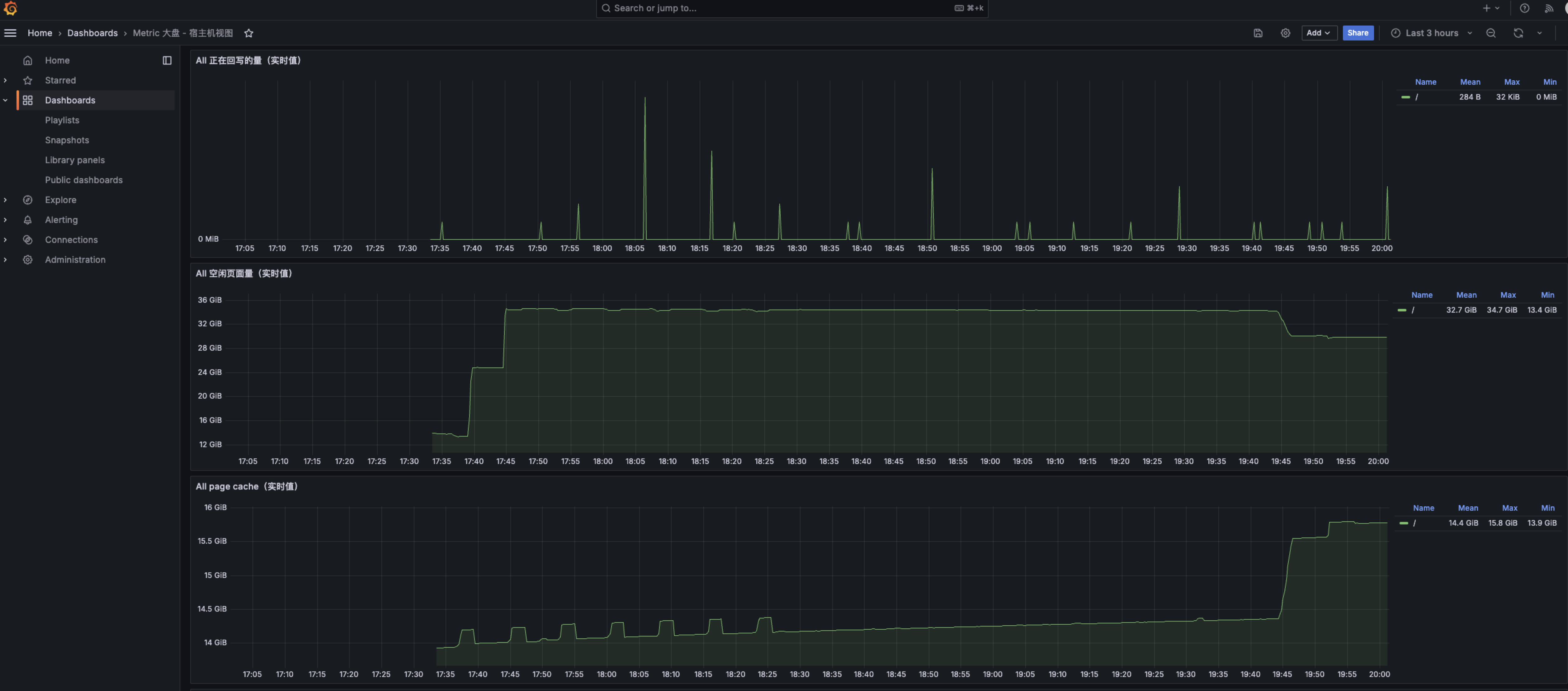
查看容器、宿主机指标大盘。打开浏览器,IP 地址为运行 HUATUO 的宿主机 IP,端口为 3000。(默认管理账户密码都是
admin)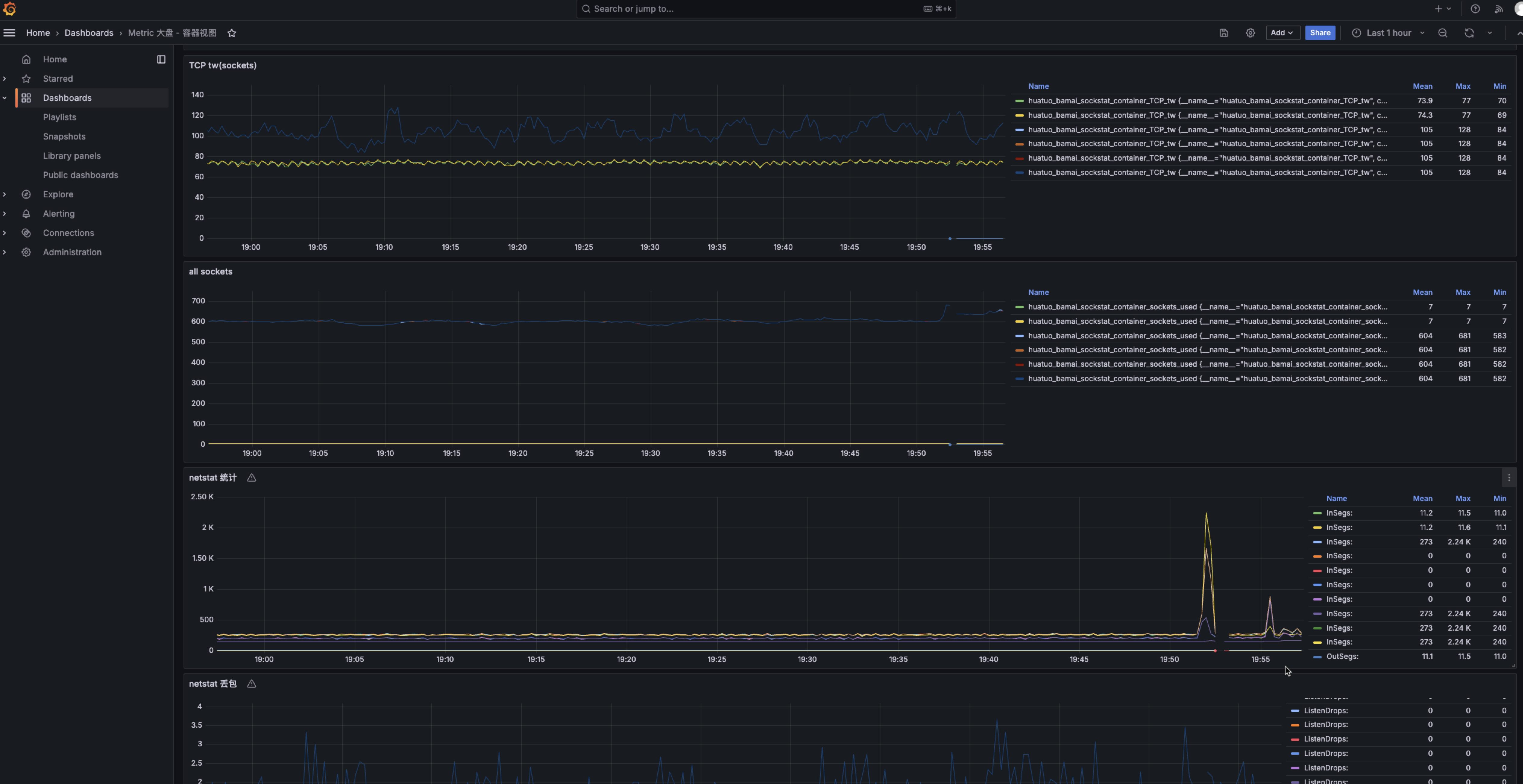
生成火焰图
有了 kubelet 管理的容器,安装好 HUATUO 组件,接下来介绍如何触发一个容器的异常行为,让 HUATUO 自动抓取火焰图。
-
在另外一个终端登录容器,并执行测试程序。
$ kubectl exec -it fedora42-795b765c6c-8p4dl -- bash $ while true; do dd if=/dev/zero of=/dev/null bs=1M count=102400; done -
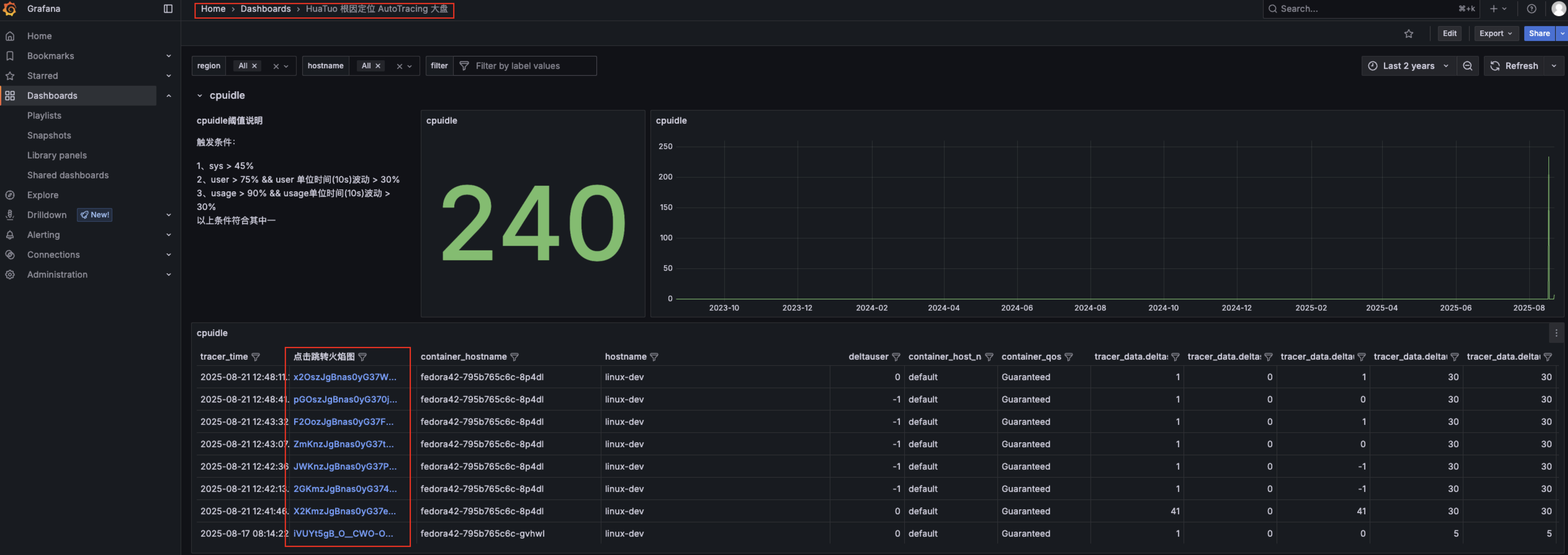
查看火焰图,打开浏览器 -> 输入ip:3000 -> Dashboards -> HuaTuo 根因定位 AutoTracing 大盘 -> cpuilde 展开
跳转后的火焰图效果:
dd是一个非常简单的程序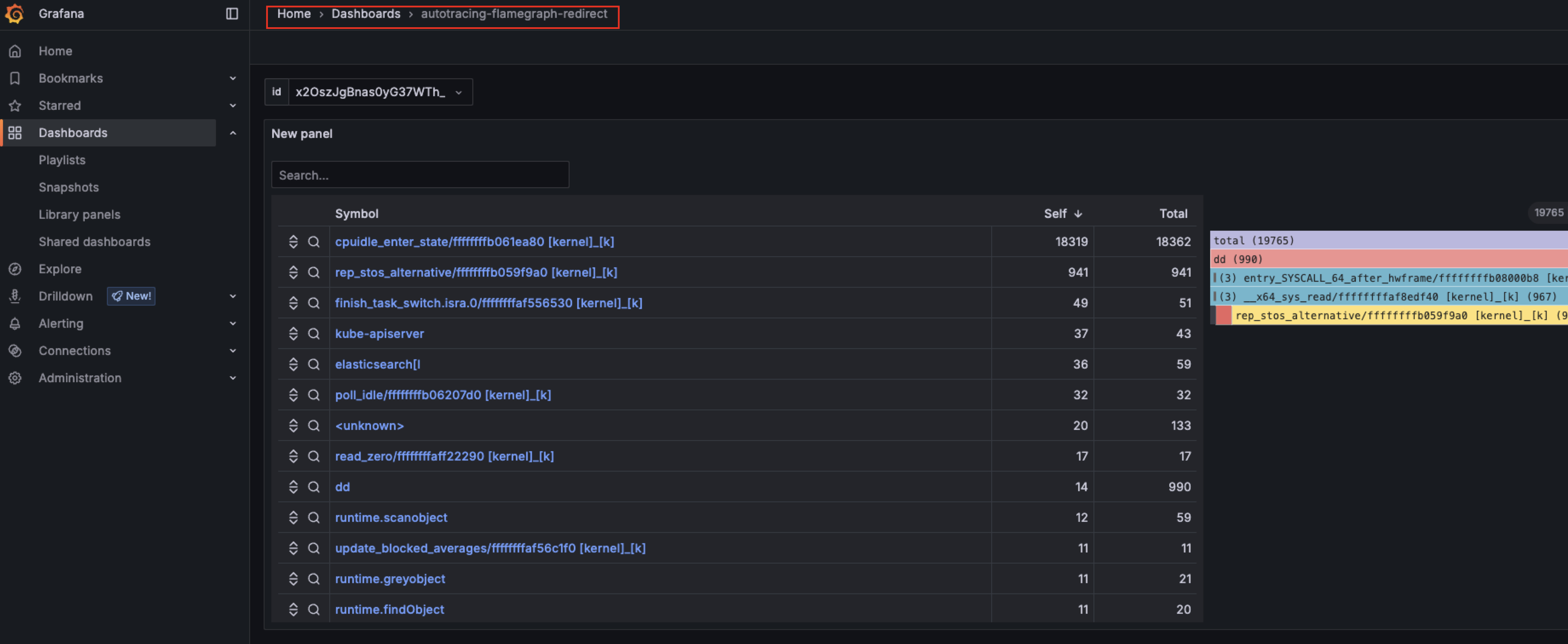
-
火焰图阈值配置,通过上面的操作,你已经得到了 CPU 掉底时的火焰图,以及故障现场各种CPU信息。此后你完全可以根据你的业务场景配置CPU 阈值。
[Tracing.CPUIdle] UserThreshold = 75 # 触发生成火焰图时的 User CPU 百分比 SysThreshold = 45 # 触发生成火焰图时的 Sys CPU 百分比 UsageThreshold = 90 # 触发生成火焰图时的 总体 CPU 百分比 DeltaUserThreshold = 30 # 触发生成火焰图时的 User CPU 增长值 DeltaSysThreshold = 0 # 触发生成火焰图时的 Sys CPU 增长值 DeltaUsageThreshold = 30 # 触发生成火焰图时的 总体 CPU 增长值 Interval = 2 # CPU 状态采集间隔 IntervalContinuousPerf = 10 # 距离上次采集火焰图的时间间隔,避免反复采集,对系统造成影响 PerfRunTimeOut = 10 # 采集火焰图持续的时间
篇尾:
- 关注微信公众号【HUATUO 开源技术】留言,或扫码添加工作人员微信,邀请您加入用户群(请备注姓名+单位):

- 代码仓库:https://github.com/ccfos/huatuo
- 官方网站:https://huatuo.tech/