
最后更新: 2026-01-07, 作者: hao022
8月2日,滴滴宣布其开源云原生操作系统可观测性项目 HUATUO 正式入驻中国计算机学会(CCF),加入其重点孵化项目序列。本次入驻不仅体现了滴滴长期践行开源共建共享的理念,也希望通过行业协作,共同推动可观测领域操作系统基础设施的高效标准化发展。

HUATUO(华佗) 是滴滴自研并开源的云原生操作系统可观测性项目,聚焦解决云原生环境中故障现场缺失、复现困难、诊断成本高等问题。面对容器漂移、架构复杂、上下游依赖多等挑战,HUATUO 基于 BPF 技术,整合 kprobe、tracepoint、ftrace 等动态追踪手段,构建了低损耗、零侵扰的多维度内核观测能力体系,包括精细化指标埋点、异常上下文捕获、系统毛刺自动追踪及多语言持续性能剖析。当前,HUATUO 已在滴滴生产环境中实现规模化部署,覆盖多类复杂故障场景,在系统高可用性保障与性能优化中发挥了关键作用。
技术架构

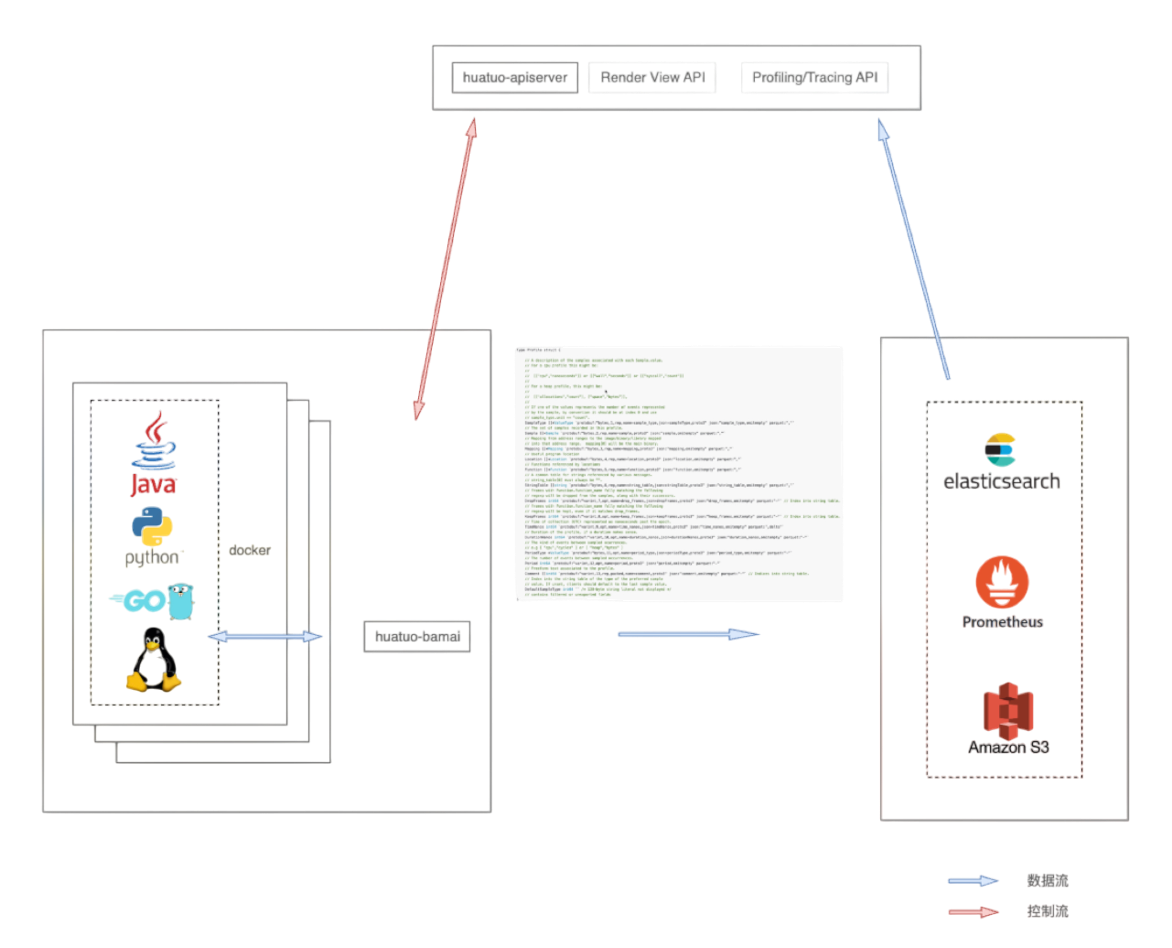
HUATUO 系统在设计上重点考量了可扩展性、易用性、稳定性、可降级性、模块独立性以及接口设计等核心要素。系统主要由底层数据采集器和 apiserver 两部分构成。上图展示了数据采集器的架构,下面主要从软件架构进行说明:
- 在指标采集方面,为提升指标的扩展性和易用性,HUATUO 实现了一套统一的指标框架。该框架向上层提供符合 Prometheus 标准的开源指标格式输出,同时向下为开发者暴露简洁的 Go 语言接口。开发者仅需实现此接口,即可高效便捷地集成新的监控指标。
- 针对内核事件处理,HUATUO 提供了专门的事件框架。该框架核心负责实时感知与处理各类内核事件,并为开发者封装了大量底层实现细节。开发者只需专注于实现一个轻量级的特定接口,即可快速扩展新的内核事件类型。
- 任务追踪管理,HUATUO 承担着管理来自 AutoTracing 和 apiserver 的完整任务生命周期的职责,确保追踪任务的顺畅执行与状态维护。
- 系统支持采集多种类型的观测数据,HUATUO 实现了统一的存储接口,后端包括本地文件系统、Elasticsearch (ES) 以及 Amazon S3 等。这一设计使得具体的存储实现细节对开发者完全透明,简化了存储选型与接入。
- 基于成熟的 Cilium BPF 库,HUATUO 重新设计了 BPF 管理功能。创新地采用 BPF 对象文件的方式,实现了业务应用逻辑与底层操作系统的解耦。
- HUATUO 支持火焰图处理功能。该功能通用强,支持处理生成 CPU 使用、内存分配、网络 I/O 等关键子系统性能瓶颈的火焰图。
- 最后,HUATUO 建立了一套关联机制,将内核数据结构体和容器信息关联。为了实现内核数据和容器信息关联,HUATUO 从云原生组件获取pod/容器信息,从内核捕获容器创建删除事件,通过cgroup id、css,容器 ID 等进行关联。
核心特性
低损耗内核全景观测
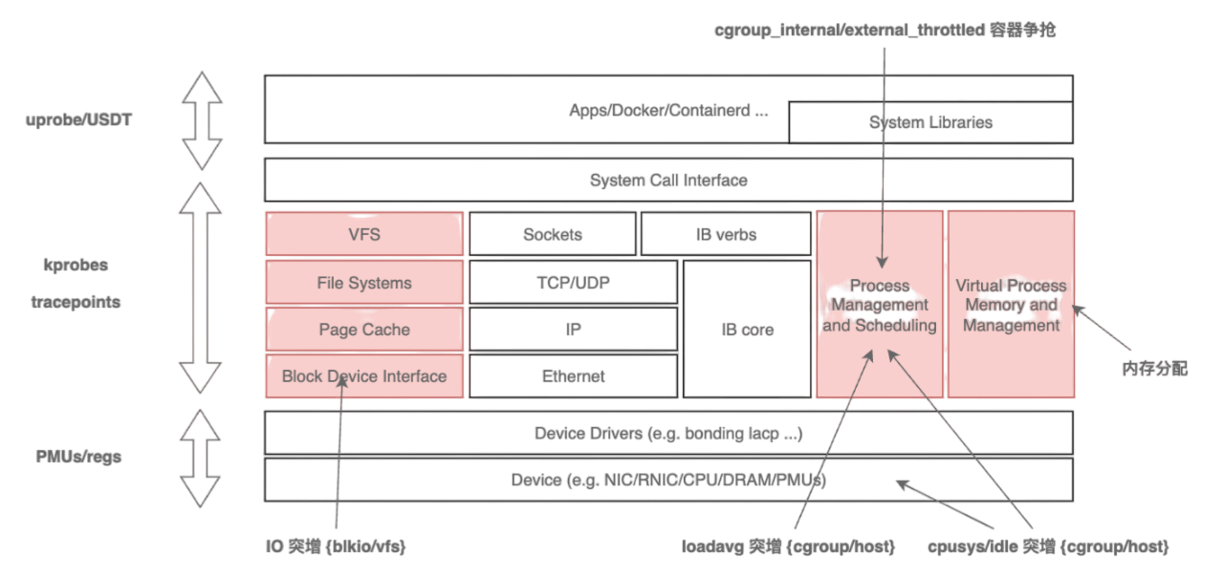
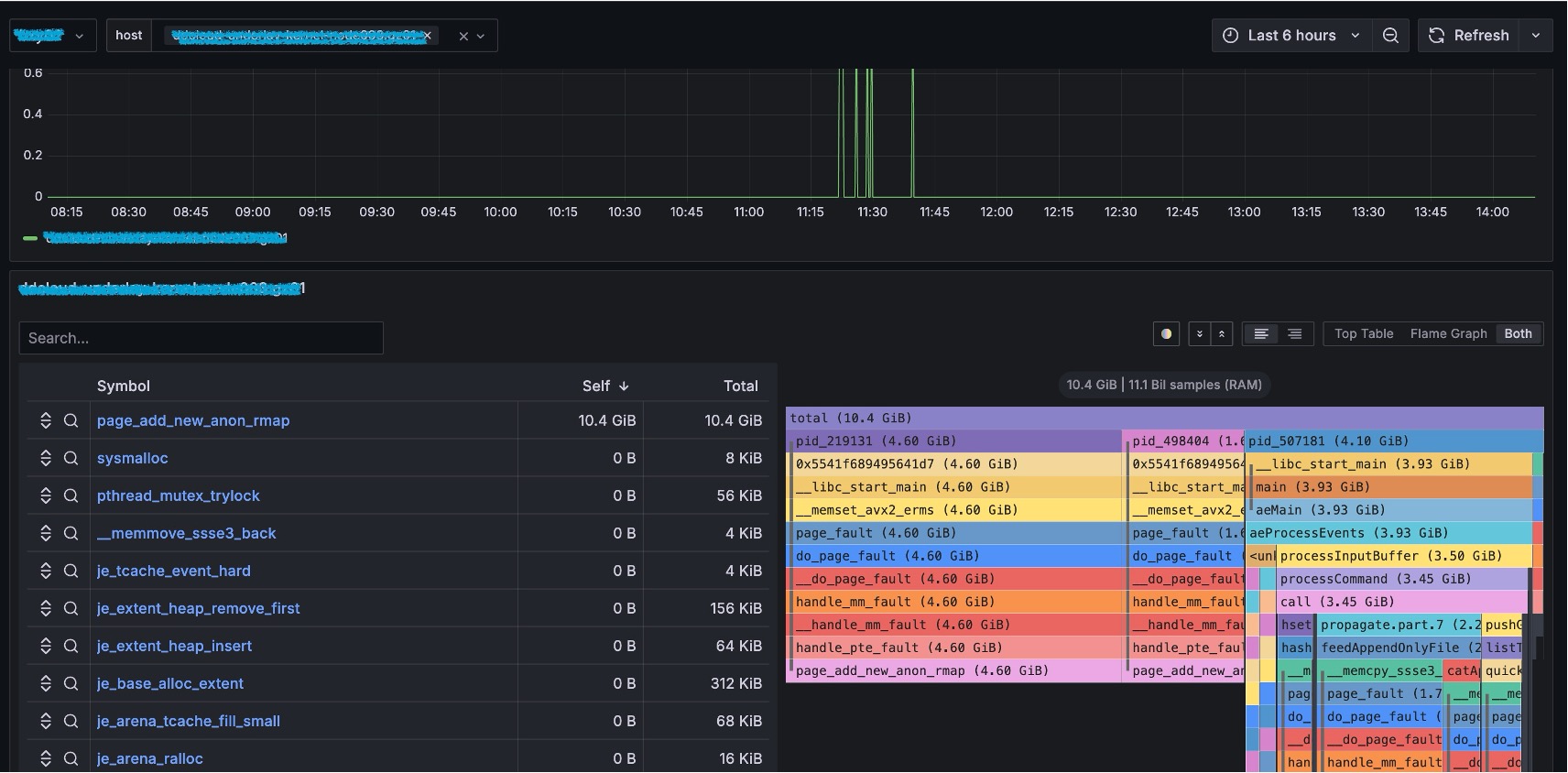
传统的 procfs 指标粒度较粗,难以回答“是谁、在哪、为何发生”等关键问题。HUATUO 针对这一痛点,深入内核各子系统的工作机制,在慢路径和异常路径进行精细化埋点,捕获关键上下文信息,并基于 BPF 技术实现无侵入、低开销的动态观测。同时,为应对高频异常可能带来的性能冲击,HUATUO 设计了“限速”机制,实现指标采集的动态降级控制。在系统架构上,项目注重扩展性:内核侧通过 BPF 减少版本依赖,实现可编程观测;应用侧则提供统一框架,支持 metric、event、tracing、profiling 等能力的灵活扩展。通过构建内核与 K8s 容器间的高效数据映射机制,HUATUO 最终实现了在性能损耗低于 1% 的基础上,对内存、CPU、网络、IO 等核心子系统的全景、细粒度观测能力。下图是对各子系统的观测点和前端效果图。
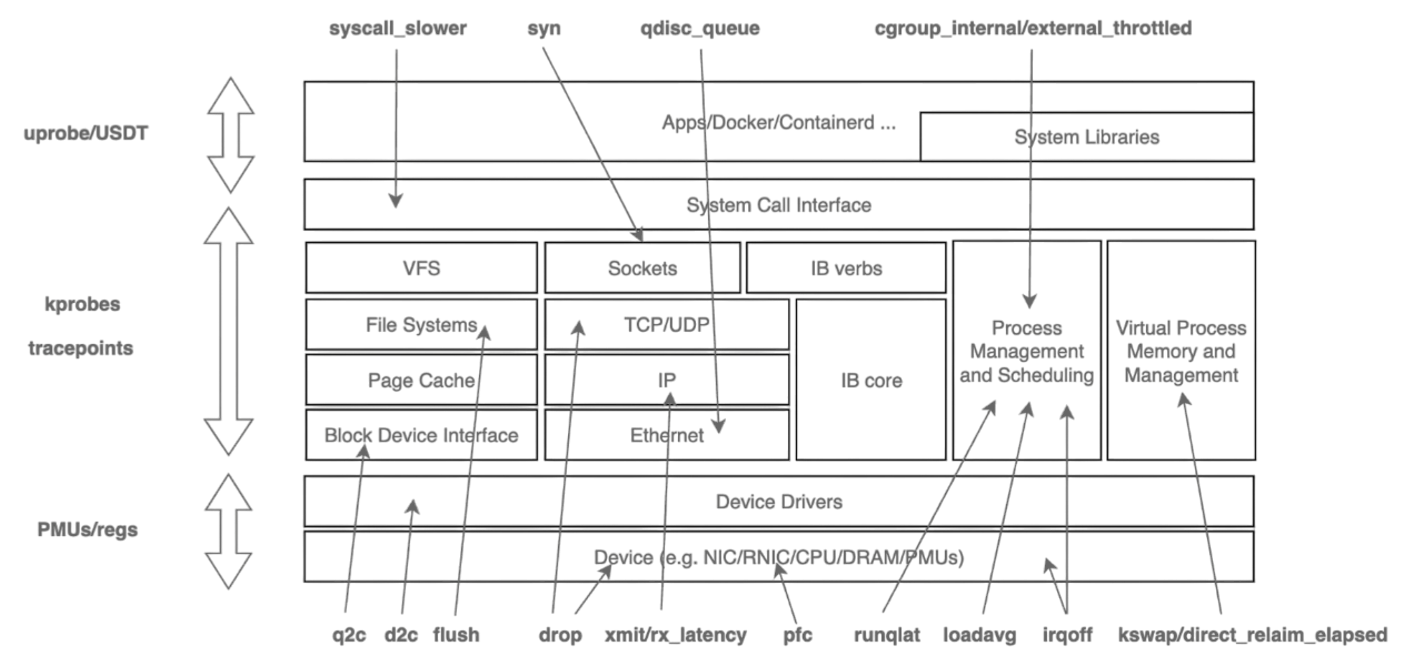
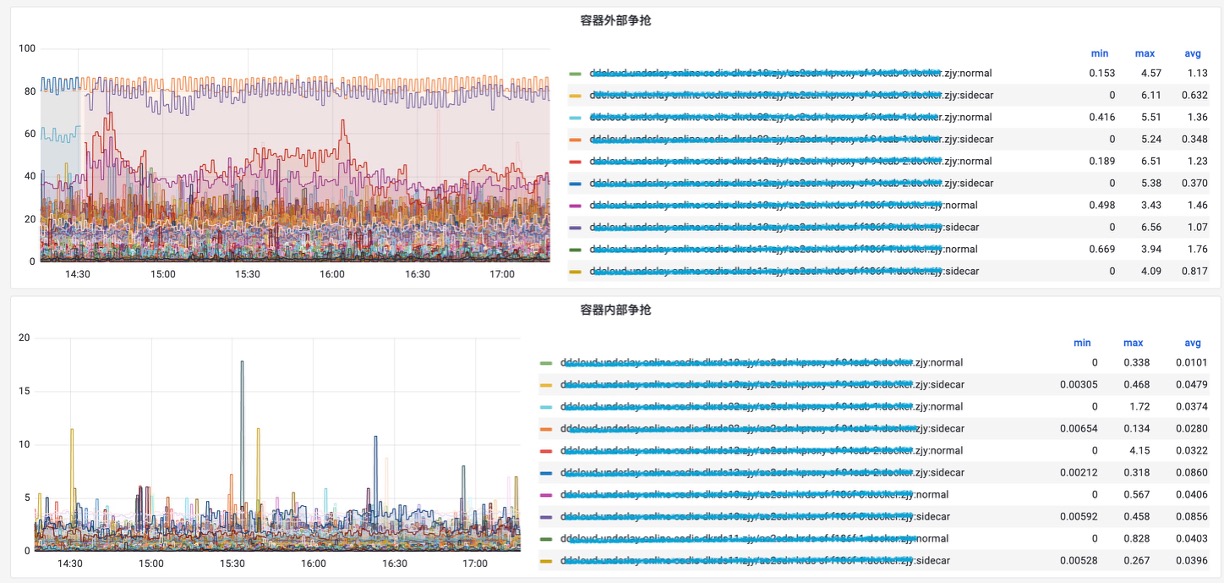
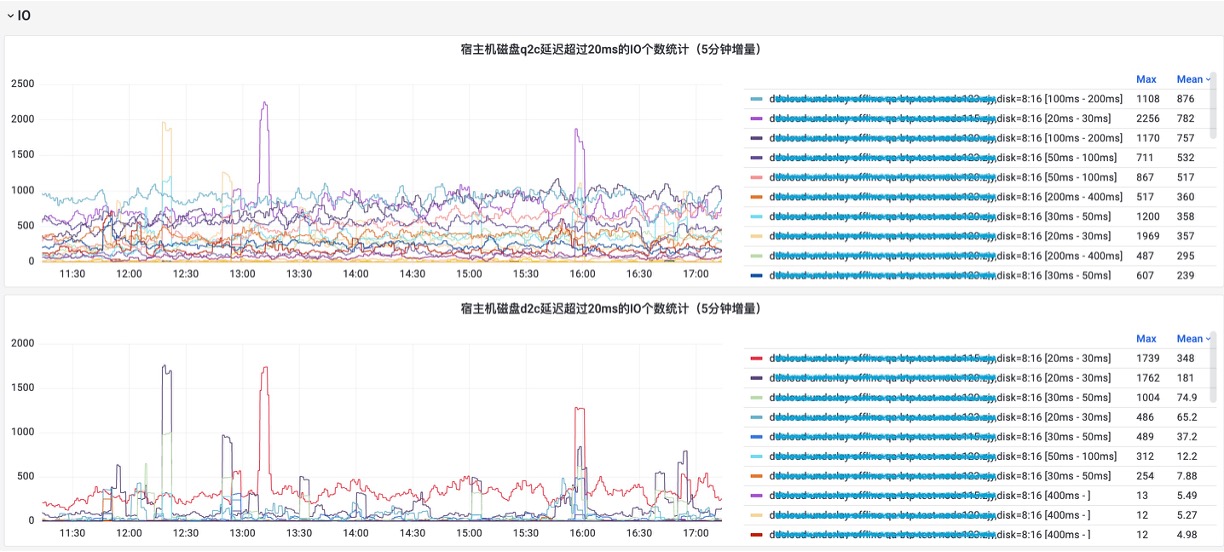
异常事件驱动诊断
指标是一种整体,持续的对系统状态的表达和描述,而事件是对指标的一种增强,能够捕获更严重的系统问题,能够捕获更多的观测数据。异常事件驱动的诊断不需要事无巨细的获取系统状态,只需要根据设定的阈值触发即可。这种方式相比指标对系统的性能损耗更小,获取的信息更多,但阈值需要打磨,或者根据用户的需求选择。那么我们关注哪些内核事件呢?从实践经验来看,需要围绕内核的进程上下文,中断上下文展开,需要关注阻塞和延迟事件,例如网络事件,调度事件,IO 事件,内存事件等等。最终 HUATUO 构建基于异常事件驱动的运行时上下文捕获机制,聚焦内核异常与慢速路径的精准埋点。当发生缺页异常、调度延迟、锁竞争等关键事件时,自动触发追踪,生成包含寄存器状态、堆栈轨迹及资源占用的图谱诊断信息。
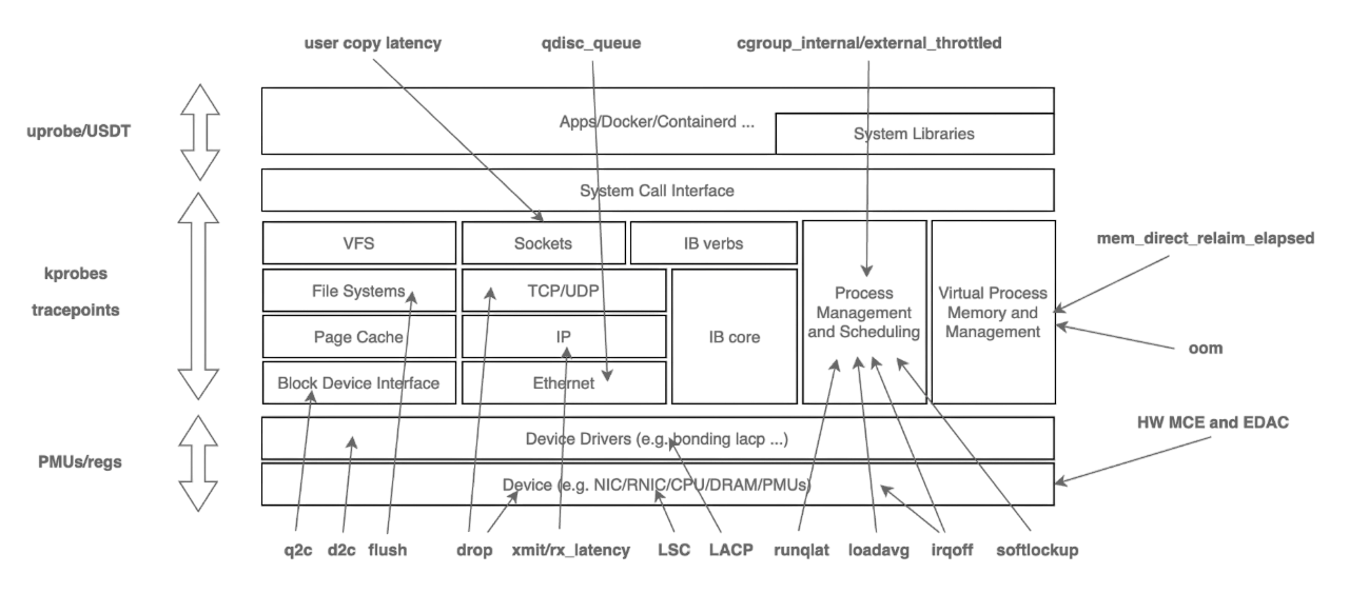

全自动化追踪 AutoTracing
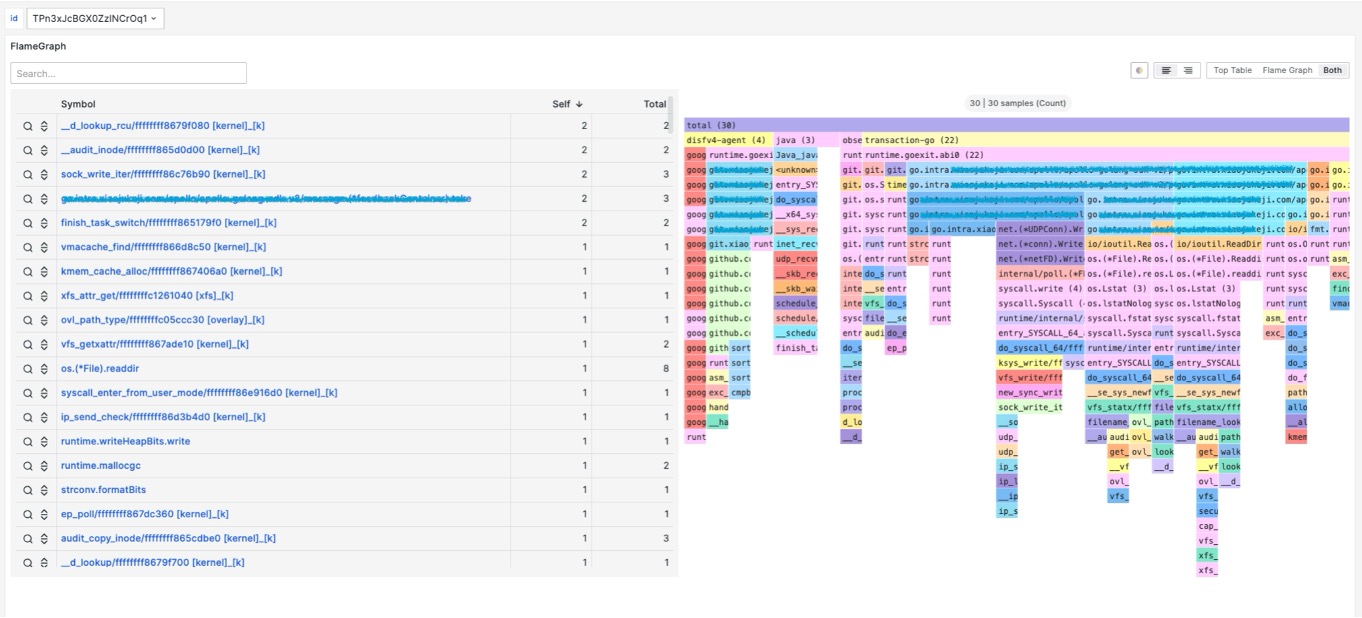
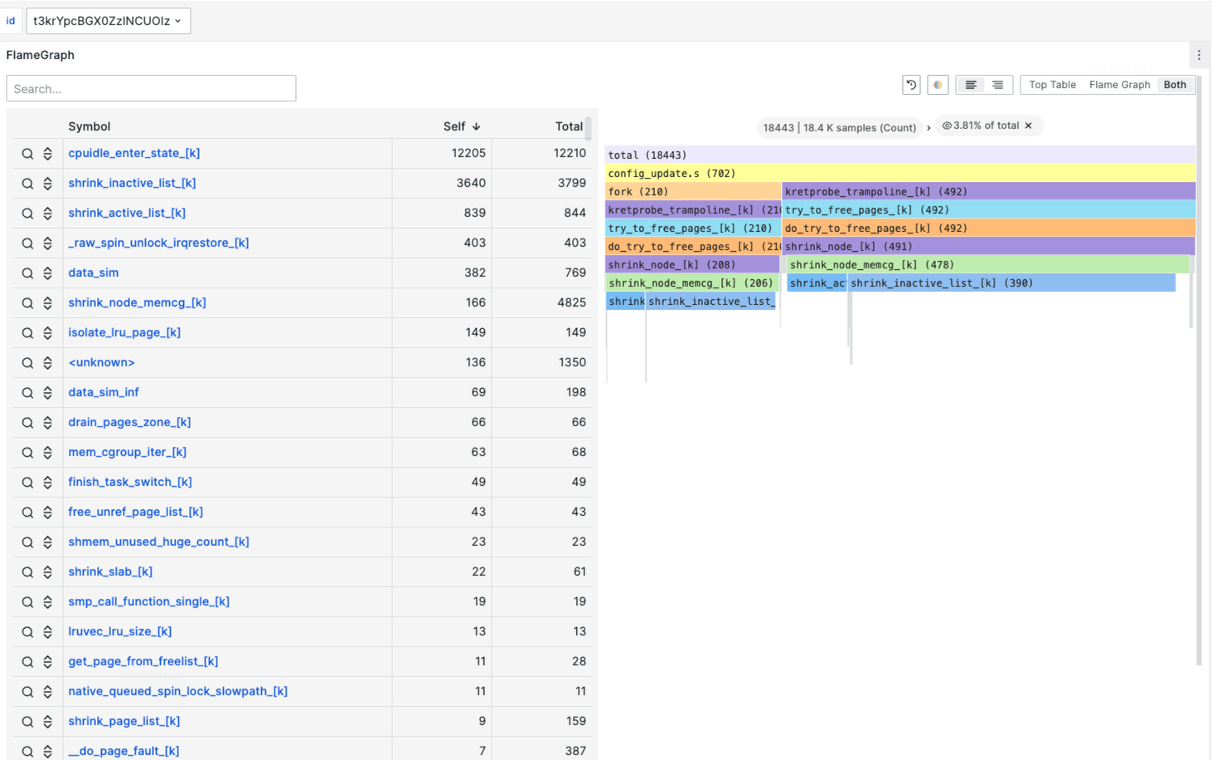
相比指标,事件,全自动化追踪是为了解决更高维度的系统,业务应用的指标突增,偶发延迟等问题设计的。该方式适合解决如 cpusys,cpuidle,IO,Loadavg,容器争抢等问题。那么如何组织观测数据?调用栈,火焰图?通过实践经验发现,火焰图能够很好的表达、展示这些突增时采集到的数据。火焰图能够表达非常丰富的信息,不局限于CPU,在内存,锁,loadavg等场景依然非常占据优势,且诊断结果简单易懂。这种全自动化的、按需的追踪也是对性能损耗和获取观测数据的有效平衡。最终总结为,AutoTracing 模块采用启发式追踪算法,解决云原生复杂场景下的典型性能毛刺故障。针对 CPU idle 掉底,CPU sys 突增,IO 突增,loadavg 突增等棘手问题,实现自动化快照留存机制和根因分析。下图是华佗通过自动化追踪方式观测的内核子系统。
持续性能剖析
操作系统观测体系已经很丰富了,为什么需要持续性能剖析?持续性能剖析在应用性能分析,故障排查,放火演练,链路压测等场景占据重要位置。这些场景需要一种持续的,可回溯的,全景的,全语言的性能剖析能力。那么剖析哪些资源?实践中,不局限于CPU,内存分布,内存分配,锁竞争等同样重要。观测这些对象的维度又是非常丰富的,例如多语言,线程,进程,线程组,进程组,容器,CPU,内核子系统等等。最终 HUATUO,通过标准化底层语言框架,提供统一的,语言无关的存储结构。通过零侵扰,低损耗的方式实现持续对操作系统内核,应用程序进行全方位性能剖析,涉及系统 CPU、内存、I/O、 锁、以及各种解释性编程语言,力助业务持续的优化迭代更新。下图为持续性能剖析的软件架构和以redis为例的内存剖析。
开源生态融合
无缝对接主流开源可观测技术栈,如 Prometheus、Grafana、Pyroscope、Elasticsearch等。支持独立物理机和云原生部署,自动感知 K8S 容器资源/标签/注解,自动关联操作系统内核事件指标,消除数据孤岛。通过零侵扰、内核可编程方式兼容主流硬件平台和操作系统发行版。
落地场景
该项目在各种场景都有应用落地,成为支撑滴滴网约车核心业务运行的重要技术保障之一。
- 链路压测 重要节假日前,各业务线都会进行稳定性链路压测,HUATUO 为这种场景提供系统故障诊断分析,持续性能剖析。
- 放火演练 业务应用放火不符合预期,则可以通过 HUATUO 查看底层系统运行状态。
- 假期护堤 节假日期间,访问流量非常高,业务应用可能出现延迟、抖动、I/O 突增和 CPU 掉地等问题。HUATUO 则会自动捕获这些事件。
- 性能剖析 业务应用在不同的集群表现有差异,则可以通过 HUATUO 分别对不同集群应用执行性能剖析,差异化分析。
- 预发灰度 HUATUO 主动发现了很多问题,例如应用程序进程突增,cordump,loadavg 突增,网络丢包等。
- 日常排障 系统软件团队负责集团业务集群底层基础设施的稳定性,日常会有很多故障排查,问题解答等工作。HUATUO 落地后在很大程度上释放了团队人力。
未来,滴滴将与中国计算机学会(CCF)一起加速 HUATUO 项目快速迭代,聚焦操作系统底层的性能剖析与分布式链路追踪,基于实现自动感知、Tracing、Profiling 等关键技术,实现零侵扰、可编程的内核监测,为各行业提供一个一站式系统化的系统故障分析解决方案。此外,在产学研合作生态支持下,不断提升技术影响力,助力打造具备全球竞争力的国产开源基础设施。
篇尾:
- 关注微信公众号【HUATUO 开源技术】留言,或扫码添加工作人员微信,邀请您加入用户群(请备注姓名+单位):

- 代码仓库:https://github.com/ccfos/huatuo
- 官方网站:https://huatuo.tech/